- 优先队列
- 二叉堆
- 二叉堆的操作: 下沉和上浮
- 优先队列的实现
- 堆排序
- 排序总结
优先队列
算法这书看到现在, 基本上能看明白算法讲什么和代码, 但是数学分析真的是看不来, 太刺激了.
堆排序是从一个优先队列的抽象数据结构引入的. 所谓优先队列, 就是一个某个长度的队列, 可以放入元素, 但是取出的时候不像最简单先进先出的队列, 而是按照一定的次序取, 比如每次总取某种排序情况下排在最前边或者后边的元素, 这就叫做优先队列.
这里的最大并不是指什么数值大小, 而是指经过排序之后的序列末尾或者开头的对象.
此时这个堆的内部数据结构就很重要了. 而且其API可能也要变化, 即每次从队列中弹出对象的时候, 总是删除并且弹出最大的对象.
我们的问题就变成了, 每次向队列添加元素的时候, 排序所有的元素. 而不是一次性将所有需要的内容进行排序, 因为队列的输入可能很多时候是连续的, 永远不会中止, 所以需要始终维持一个排序的结构.
优先队列的API如下:
public class MaxPQ<Key extends Comparable<Key>>
MaxPQ() //创建空优先队列
MaxPQ(int max) //创建长度为Max的优先队列
MaxPQ(Key[] a) //通过Key对象数组创建优先队列
void Insert(Key v) //向队列中添加元素
Key max() //返回最大元素
Key delMax() //删除并返回最大元素
boolean isEmpty() //队列是否为空
int size() //队列中元素的长度
可以看到, 关键的变化就是Insert的时候要进行排序, 而max函数要从排序后的对象中找到, 还可以删除之. 关键就是高效的实现Insert和delMax函数, 换言之, 就是如何实现高效排序和查找.
算法书上先是探讨了几种实现:
- 队列内部使用数组的话, 如果组织成栈的方式, 可以使用选择排序, 每次插入元素的时候排一次, 将最大的排在末尾, 这样的delMax()就和pop()函数一样
- 和上边一样, 但是使用插入排序, 每次新插入一个元素就排一次, 始终弹出最末尾的元素
- 使用基于链表的结构, 插入和选择都类似上边
上边的结构无论是哪一种, 在插入和删除元素的时候, 二者至少有一个复杂度是N级别的. 如果想让理想情况都是接近常数级别的, 就要引入一个新的数据结构: 堆
二叉堆
为了让优先队列的使用效率提高的对数级别, 就要来看一个新的数据结构: 二叉堆.
二叉堆的核心是: 每个元素都要大于另外两个特定位置的元素(也可以看成是子节点的两个元素). 当一颗二叉树的每个节点都大于等于两个子节点,这个二叉堆就叫做堆有序.
根节点是最大的节点, 从任意节点往上, 都可以得到一串非递增的元素, 往下则可以得到非递减的元素.
二叉堆要用什么数据结构表示呢? 如果将每个节点看做对象, 则这个对象需要三个指针, 一个指向父节点, 两个指向两个子节点.
如果使用完全二叉堆(即根节点已经定义好,一层层往下画的二叉树), 就可以用数组来表示了. 这一章就是用的数组表示.
用数组表示二叉堆, 第一个索引空着不用. 这样根节点是1, 两个子节点是2和3, 2的子节点是4和5, 3的子节点是6和7, 再往下4的子节点是8和9....
这发现了一个规律, 除了根节点之外, 一个索引为i的节点的两个子节点是 2i 和 2i+1 , 父节点的索引是 i/2. 这样通过索引可以很方便的在堆中找到想操作的索引.
用数组实现二叉堆, 灵活性不如使用指针的二叉树, 然而可以利用数组的便捷操作提高效率, 因为无需利用指针上下移动, 而是通过直接索引.
二叉堆的操作: 下沉和上浮
注意看二叉堆的性质, 即每个元素都大于另外两个子节点的元素, 所以当一个元素新加入堆的时候, 可以将这个元素上浮或者下沉到正确的位置, 让整个堆重新变的有序.
所谓下沉, 就是不断的比较当前元素与两个子节点元素的大小, 如果大于等于, 那就说明处在了正确的位置, 如果小于, 则需要把当前元素与两个元素里比较大的一个进行交换.
不断这样下沉, 最终就会到达正确的位置.
下沉的代码是这样的:
private void sink(int k) {
while (k * 2 < N) {
int j = 2 * k;
if (j < N && less(j, j + 1)) {
j++;
}
if (!less(k, j)) {
break;
}
exch(k, j);
k = j;
}
}
下沉的代码我仔细看了看, 由于在操作中都是从1开始下沉, 走几个循环看看, 比如一共有3个节点, 则N=3
所谓上浮, 就是不断的比较当前元素与父节点, 如果大于父节点, 就交换两者的位置, 直到索引为1为止. 由于1的节点是放在2和3的, 如果要下沉, k = 1的时候, 小于N=2, 然后j=2, 由于j已经等于N,所以不会做判断来增加j(就是取到下一个子节点), 然后比较二者之后交换j.
不得不说代码还是很简洁的, 如果我自己写, 可能要多好几个变量.
优先队列的实现
有了核心的上浮和下沉代码, 就可以来写出内部是二叉堆结构的优先队列了, 完整代码如下:
public class MaxPQ<Key extends Comparable<Key>> {
private Key[] pq;
private int N = 0;
public MaxPQ(int maxN) {
pq = (Key[]) new Comparable[maxN + 1];
}
public boolean isEmpty() {
return N == 0;
}
public int size() {
return N;
}
public void insert(Key v) {
pq[++N] = v;
swim(N);
}
public Key delMax() {
Key max = pq[1];
exch(1, N--);
pq[N + 1] = null;
sink(1);
return max;
}
private boolean less(int i, int j) {
return pq[i].compareTo(pq[j]) < 0;
}
private void exch(int i, int j) {
Key t = pq[i];
pq[i] = pq[j];
pq[j] = t;
}
private void swim(int k) {
while (k > 1 && less(k / 2, k)) {
exch(k / 2, k);
k = k / 2;
}
}
private void sink(int k) {
while (k * 2 <= N) {
int j = 2 * k;
if (j < N && less(j, j + 1)) {
j++;
}
if (!less(k, j)) {
break;
}
exch(k, j);
k = j;
}
}
}
优先队列在插入元素的时候, 将元素插入到最后, 然后用swim()恢复堆的秩序. 在删除元素的时候由于是优先级, 始终删除索引1的元素, 将其与最后一个元素对调, 然后将最后一个元素的位置设置为null, 更新N, 然后对索引1位置的元素进行下沉操作, 重新恢复堆的有序性.
这样加入数据一直在流入, 堆内固定长度的数组里, 永远是有序的, 不管何时弹出, 总归是弹出当前最大的元素. 这就实现了优先队列.
堆排序
将堆扩展一下, 扩展到一个和要排序的东西相同长度(从1开始的索引, 实际上长度是N+1), 然后对这个数组使用sink和swim方法, 这就是全新的排序方法, 堆排序.
堆排序主要有两个步骤:
- 构造堆, 由于要排序的元素可能并不符合堆的要求, 这里有个巧妙的办法, 就是从堆的右侧开始操作, 用sink函数, 从堆中间开始向左逐渐把元素都下沉下去. 由于堆的特性是二叉的, 所以从中间索引开始就可以保证sink成功.
- 不断将最大的元素换到尾部, 然后缩减堆的长度, 直到堆变空. 只要成功的构造了堆, 其顶部就是最大的元素. 然后将其和最后一个元素交换, 再缩减堆的长度, 然后继续把最后一个元素下沉完, 再重复这个过程, 其本质就是每次都从堆里找出最大的元素然后放到堆外部.
这两个步骤执行完毕之后, 就排完了. 代码如下:
public static void sort(Comparable[] pq) {
//这个pq不需要放入一个索引从1开始的队列里
int n = pq.length;
//构造堆, 从索引的一半开始.
for (int k = n/2; k >= 1; k--)
sink(pq, k, n);
//不断的交换之后, 减少堆, 然后下沉第一个元素
while (n > 1) {
exch(pq, 1, n--);
sink(pq, 1, n);
}
}
这里注意exch和less实际上将索引减少了1, 于是索引就能够在从0开始的数组上进行操作了. 完整的Heap.java 如下:
public class Heap {
private Heap() { }
public static void sort(Comparable[] pq) {
int n = pq.length;
for (int k = n/2; k >= 1; k--)
sink(pq, k, n);
while (n > 1) {
exch(pq, 1, n--);
sink(pq, 1, n);
}
}
private static void sink(Comparable[] pq, int k, int n) {
while (2*k <= n) {
int j = 2*k;
if (j < n && less(pq, j, j+1)) j++;
if (!less(pq, k, j)) break;
exch(pq, k, j);
k = j;
}
}
private static boolean less(Comparable[] pq, int i, int j) {
return pq[i-1].compareTo(pq[j-1]) < 0;
}
private static void exch(Object[] pq, int i, int j) {
Object swap = pq[i-1];
pq[i-1] = pq[j-1];
pq[j-1] = swap;
}
// print array to standard output
private static void show(Comparable[] a) {
for (int i = 0; i < a.length; i++) {
StdOut.println(a[i]);
}
}
public static void main(String[] args) {
String[] a = new String[]{"fds", "83", "df89", "83", "vv", "cony", "jeny"};
Heap.sort(a);
show(a);
StdOut.println(Insertion.isSorted(a));
}
}
不得不说堆排序真的是妙啊.
排序总结
算法学到现在感觉就和看物理书一样, 先是一堆人名发明了这些算法, 然后是一堆数学证明. 对于少年时候数学很烂的我, 确实抽象思维能力还不够好, 看不懂证明也想不到其中的联系.
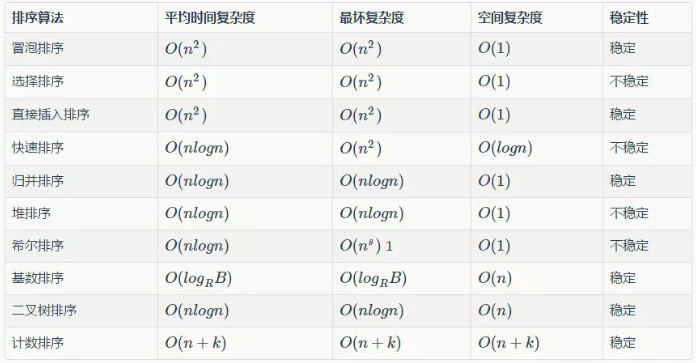
不过至少可以把算法当成一个工具了, 了解了这些排序算法的实质, 在做一些题目的时候, 就可以根据情况有效的来使用算法了. 放个总结图, 算法这东西想要一次性搞明白还是没那么简单的. 上个图留一下, 其中的二叉树下一章就要来了: