
制作分享内容的功能
如果一个网站是需要向多个用户或者向公众提供服务的(之前的博客可以说是单用户系统),在引入了用户验证系统之后,整个网站的功能设计基本上都是围绕用户开展的。就像主流的大型网站如电商和社交网站,所有的功能都是基于用户角色开展的。
本章开始的内容逐渐硬核。要实现通过JavaScript小书签程序从其他网站将内容分享到这个网站的功能,以及在Django中使用jQUERY来发送AJAX请求。主要内容有:
- ORM中的多对多关系
- 自定义表单的行为
- 使用jQuery
- 建一个jQuery bookmarklet
- 给图片建立缩略图
- 使用AJAX功能和视图
- 给视图建立自定义装饰器
- 用AJAX分页
制作图片书签功能
开始之前分析一下需求,想实现的功能是:用户在本网站和其他网站发现的图片,可以收藏和分享,要做以下几件事情。
- 用一个数据类存放图片和相关信息
- 建立表单和视图用于控制图片上传
- 需要建立一个系统,让用户如果在外网发现了图片,也能贴到本站来。
刚才的用户相关的功能全部放在了account应用下边,现在我们使用一个新的app 叫做 images。建立之后老样子配置到INSTALLED_APPS里。
建立图片数据类和保存数据的方法。
from django.db import models
from django.conf import settings
class Image(models.Model):
user = models.ForeignKey(settings.AUTH_USER_MODEL, related_name='images_created', on_delete=models.CASCADE)
title = models.CharField(max_length=200)
slug = models.CharField(max_length=200,blank=True)
url = models.URLField()
image = models.ImageField(upload_to='images/%Y/%m/%d')
description = models.TextField(blank=True)
created = models.DateField(auto_now_add=True,db_index=True)
def __str__(self):
return self.title
一个用户上传的图片可以有多个,所以图片和用户的关系是一对多,因此在多的那一边使用外键关联到User表。其他要解释的就是created里边用db_index参数建立了索引。对于经常使用filter等之前介绍过的列建立索引,可以提高查询效率。
还要给这个模型自定义一些行为。这里开始自定义的东西就多了起来:
# 重写.save()方法,自动添加slug
def save(self, *args, **kwargs):
if not self.slug:
self.slug = self.title
super(Image, self).save(*args, **kwargs)
如果不存在slug就用标题当做slug,然后调用父类的方法来保存图片。
然后继续修改这个Image类。之前我们建立了外键user,这表示这个图片是谁上传(来源于哪个用户)的,还需要一个字段记录哪些用户喜欢这个图片。这个时候两张表之间的关系,就不再是一对多或者一对一了。一张图片可以有很多个用户喜欢,一个用户会喜欢很多张图片,从两张表的每行数据的角度来看,都是一对多的关系,这样的表与表之间的关系,就是多对多关系。
由于在数据库里没有这种关系,只有外键,所以现在可以总结一下:
- 一对一就是unqiue 的外键,不允许重复,本质上相当于一张表的扩展。其中外键字段是独特的,不允许重复。
- 一对多就是普通外键,在多的那一方建立。多那边的每一个数据只允许关联一个外键,即数据+外键的组合是独特的。
- 多对多就是通过一张中间表建立关系,中间表两个外键一个连到表A,一个连到表B,中间表的两个外键的组合是独特的。
那么就在Image类里继续添加一个多对多的关系字段:
users_like = models.ManyToManyField(settings.AUTH_USER_MODEL, related_name='images_liked',blank=True)
多对多的字段和其他的关系字段类似,第一个参数就是关联的表。多对多字段可以设置在两张表的任何一侧,不像外键在一对多的关系中设置在多的那侧,在一对一的关系中设置在扩展的那一侧。
建立了多对多之后,需要知道的是,在一对一和一对多的关系中,直接调用外键属性,得到的是一个数据。在多对多中,直接调用外键属性名,相当于到另外一张表里去查询了所有和当前字段有关系的数据,相当于一个模型管理器来使用。所以需要查询一张表被哪些用户喜欢,只要使用 image.users_like.all()即可。
完整的Image类如下:
class Image(models.Model):
user = models.ForeignKey(settings.AUTH_USER_MODEL, related_name='images_created', on_delete=models.CASCADE)
title = models.CharField(max_length=200)
slug = models.CharField(max_length=200, blank=True)
url = models.URLField()
image = models.ImageField(upload_to='images/%Y/%m/%d')
description = models.TextField(blank=True)
created = models.DateField(auto_now_add=True, db_index=True)
users_like = models.ManyToManyField(settings.AUTH_USER_MODEL, related_name='images_liked',blank=True)
def __str__(self):
return self.title
def save(self, *args, **kwargs):
if not self.slug:
self.slug = self.title
super(Image, self).save(*args, **kwargs)
之后就可以makemigration 和migrate了,之后还是老套路,将Image类加到管理后台去。admin.py里的内容:
from django.contrib import admin
from .models import Image
@admin.register(Image)
class ImageAdmin(admin.ModelAdmin):
list_display = ['title', 'slug', 'image', 'created']
list_filter = ['created']

从其他网站分享内容过来
这个功能实际上就是用户从按照一个固定的格式访问我们的站点,站点就可以把图片下载回来,然后把相关信息放到Image数据中。
还是重复表单-->视图-->URL-->模板的思路:
from django import forms
from .models import Image
class ImageCreateForm(forms.ModelForm):
class Meta:
model = Image
fields = ('title', 'url', 'description',)
widgets = {
'url': forms.HiddenInput,
}
表单这里有一个新的内容,就是在不重写某个字段的情况下,通过widget参数,给指定的字段名配置widget。
这里还没完,有一个字段是URL,这个默认的验证器在URL只要符合一般的URL的时候就通过,但是我们需要保存图片,因此这个URL的结尾一定是图片的后缀名,所以要给url增加一个自定义的验证器,以验证URL是否是一个图片的URL。
def clean_url(self):
url = self.cleaned_data['url']
valid_extensions = ['jpg', 'jpeg', 'png', 'bmp', 'gif']
extension = url.rsplit('.', 1)[1].lower()
if extension not in valid_extensions:
raise forms.ValidationError("The given URL is not a image")
return url
自定义验证器对url使用内置切分方法,然后取后缀名进行比较。逻辑很简单。这样就可以保证URL指向一个图片了。
在这个步骤里最后要解决的问题就是通过URL来获取图片了。当用户提交的数据都完成的时候,我们在之前的项目里是实例化一个表单类,然后直接调用表单类的.save()方法就把表单类存到了新的或者instance参数指定的数据对象中。这一次我们来重写.save()方法,让用户提交成功之后,就自动下载然后保存到数据库中。
在ImageCreateForm类中继续编写:
from urllib import request
from django.core.files.base import ContentFile
from django.utils.text import slugify
def save(self, force_insert=False, force_update=False, commit=True):
image = super(ImageCreateForm, self).save(commit=False)
image_url = self.cleaned_data['url']
image_name = '{}.{}'.format(slugify(image.title), image_url.rsplit('.', 1)[1].lower())
# 下载图片
response = request.urlopen(image_url)
image.image.save(image_name, ContentFile(response.read()), save=False)
if commit:
image.save()
return image
这个表单类的save方法的逻辑如下:
- 先调用超类的save方法,建立一个新的image数据对象
- 获取url和图片名称,这其中用内置的slugify来处理标题,拆分url得到图片后缀,这相当于是用用户提供的名称给这个图片重新命名。
- 调用了image类的image字段的.save()方法,传进去的是名称和读出的内容。
- 最后是为了让行为和原来一致,只有commit=True的时候才会去真正将表单对象写入数据库。
- image.image是Image类中的Imagefield字段,Imagefield字段的save方法继承自Filefield字段:FieldFile.save(name,content,save=True)手动地将一个文件内容关联到该Field,name是调用后文件的名称,content是要关联的文件的内容,save表示该实例是否在调用完成后就执行保存到数据库。注:这里的content必须是一个django.core.files.File的实例,而不是python内置的file对象,但是可以通过用python内置的open方法获得file对象后构造一个File实例。这里的File实例就是ContentFile生成的对象。
- 再梳理一遍这个自定义方法的逻辑:先把现有的字段通过父类方法执行一下,暂时存储但是不写进数据库,表单字段只有'title', 'url', 'description',这个时候当前数据对象里还有user和 image两个必须有的字段没有存进来。然后去下载文件生成名称和文件对象,调用image.image.save()方法存了image字段。下边的视图函数给form配上了user为当前的user。最后model的save方法把slug存了进去,这样各个字段都齐全了。
解决了数据存储的问题,现在来编写视图:
from django.shortcuts import render, redirect
from django.contrib.auth.decorators import login_required
from django.contrib import messages
from .forms import ImageCreateForm
@login_required
def image_create(request):
if request.method == "POST":
form = ImageCreateForm(request.POST)
if form.is_valid():
cd = form.cleaned_data
new_item = form.save(commit=False)
new_item.user = request.user
new_item.save()
messages.success(request, 'Image added successfully')
return redirect(new_item.get_absolute_url())
else:
form = ImageCreateForm(data=request.GET)
return render(request, 'images/image/create.html', {'section': 'images', 'form': form})
这个视图需要解释以下几点:
- 首先是为什么使用GET获取数据生成请求,是因为在后边用JS发分享链接到我们的视图,会传入title和url,就会用这个来生成基础的表单展示,后续让用户再完整填写,只有收到POST请求的时候才会去下载图片。
- 如果POST请求提交,然后都验证通过,那么建立一个新的Image对象,但是不能保存,因为外键还没有关联,必须取得当前的用户,赋给Image类的外键,才能够保存
- 这里使用的redirect方法,在成功的完成了保存之后,会跳转到新保存的图片的detail页面。但是现在还没有编写Image Model的该方法,之后编写。
- new_item = form.save(commit=False) 这是一个以前忽略的点:form对象调用.save()方法的时候,会返回这个表单对应的数据对象,这个数据对象就保存了当前form里已经有的数据。在这里,new_item就是当前表单执行了save之后返回的Image类的一个新实例,其中的字段只有form表单显式指定的title,url和description三个字段,以及执行了ImageCreateForm表单类里被重写的save方法之后新增的image字段(也就是那个图片)。之后再执行的new_item.save()方法是Image ORM类里重写的.save()方法,用于生成slug,此时除了users_like字段所有的信息都完全生成,可以写入数据库了。Print一下new_item的类型就可以发现是
<class 'images.models.Image'>
整理思路
上边的部分编写完毕以后,可以看出来一个雏形,就是通过一个GET类型的链接访问这个视图,然后自动生成一个页面,只要用户点击,就可以把这个图片上传到本站。
在具体处理数据的过程中,Image类的全部字段是被各个击破的,首先是表单类显式指定了三个字段url, title 和 description,这三个通过外部链接的GET请求拿到。之后重写表单类的save方法通过拿到的URL将图片保存在image字段里。然后调用表单类的save方法得到数据对象,再给数据对象配上当前用户的user赋给外键,最后调用数据对象被重写过的save方法增加slug。这样除了users_like字段全都生成了。
目前在写入之后,会报错,因为Image类里没有定义 .get_absolute_url()方法。不过由于跳转是在数据保存后才完成的,所以数据依然被写进了数据库。
为了方便,书里提供了一个测试链接,也贴出来方便使用:测试链接。
主要是都重写了model 和 form 的save方法,看着有点绕,只要知道form.save()返回的是一个model对象就会清楚很多了,通过form-->form.save-->view赋值-->model.save的方式逐步补全了字段
继续编写urls.py和create.html
# images/urls.py, 新增creete/路径
path('create/', views.image_create, name='create'),
# main urls.py 主路由里把分支路由添加上
path('images/', include('images.urls', namespace='images'))
{# create.html #}
{% extends "base.html" %}
{% block title %}Bookmark an image{% endblock %}
{% block content %}
<h1>Bookmark an image</h1>
<img src="{{ request.GET.url }}" class="image-preview">
<form action="." method="post">
{{ form.as_p }}
{% csrf_token %}
<input type="submit" value="Bookmark it!">
</form>
{% endblock %}
urls.py和视图的配置比较简单,页面通过url显示这张图片,然后表单里有一个隐藏的url。实际提交表单的时候,再执行保存图片的动作。这样就完成好了通过一个固定的GET请求建立一个页面然后保存图片的功能。
通过测试连接传入的图片示例页面如下:
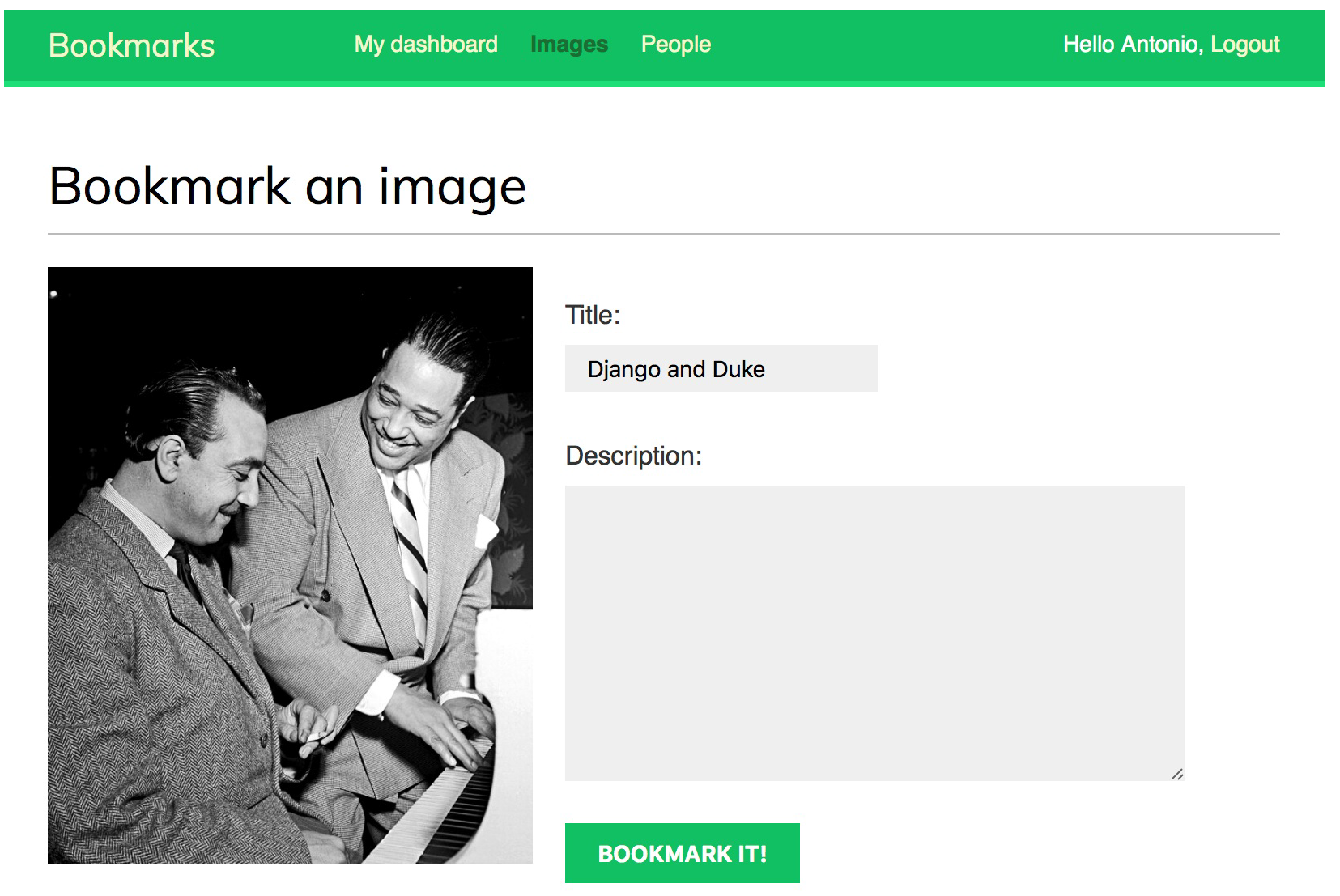
使用jQuery建立小书签 bookmarklet
bookmarklet在wiki上叫小书签,是以URL的形式被保存为浏览器的书签,点击时小书签执行一些功能。
小书签其实就是一个JS程序,和我们通常上网时候保存的单纯网站地址的书签不同,小书签以javascript:开头。后边的部分会被浏览器按照JS代码解释。所以可以在当前页面执行一些程序。
我们这里就打算写一个小书签程序,放在浏览器上,用户看到想分享的链接,就可以通过这个小程序将链接分享到我们的网站。前端所有东西感觉阮一峰都写过相应的文章,小书签也不例外。
用户将会这样使用我们的小书签:
- 用户将我们网站上的一个链接拖到浏览器的书签栏中,代码就会保存到浏览器的书签里
- 到任何其他网站上点击这个书签,小书签程序就会运行
这样做有一个问题,就是用户第一次添加了书签之后,一般不会再更新书签,我们便很难再更新其中的程序。一个替代的做法是,小书签里只放一个启动程序,实际执行的时候从一个URL里去执行实际的代码,这样就可以更新代码了。只是这么说大概还想不到如何去实现,下边开始编写代码:
编写JS程序
需要让用户拖到浏览器书签栏里的小书签程序一般长这个样子: <a href="javascript:alert('hi');">xxx</a>,按照刚才的想法,我们必须要编写一个页面让用户拖其中的链接,还需要编写一个JS程序,用于小书签内的启动器链接到这个JS程序。
在images/templates/下边新建一个bookmarklet_launcher.js:
(function () {
if (window.myBookmarklet !== undefined) {
myBookmarklet()
}
else {
document.body.appendChild(document.createElement('script')).src = 'http://127.0.0.1:8000/static/js/bookmarklet.js?r=' + Math.floor(Math.random() * 99999999999999999999);
}
})();
这段代码的意思是,如果当前页面已经有了myBookmarklet这个函数的话,就执行这个函数,如果没有,就去当前页面的body里添加一个script标签,src为 "http://127.0.0.1:8000/static/js/bookmarklet.js?r=xxxxxxxxxxxxxxxxxxxx",也就是导入了我们网站的一段JS程序并且执行。
前边先判断是否存在的原因是避免用户反复点击从而反复加载。后边使用随机数的原因是避免浏览器直接从缓存中读取程序,而是每次都会去读取最新的程序。
这就是一个启动器,用于加载实际上位于我们站点上的bookmarklet.js然后在当前页面运行。
下一步就是来给用户增加将启动器加入书签栏的页面,这些内容都展示在用户自己的登录页面dashboard.html上:
{% with total_images_created=request.user.images_created.count %}
<p>Welcome to your dashboard. You have bookmarked {{ total_images_created }} image{{ total_images_created|pluralize }}.</p>
{% endwith %}
<p>Drag the following button to your bookmarks toolbar to bookmark images from other websites <a href="javascript:{% include "bookmarklet_launcher.js" %}" class="button">Bookmark it</a></p>
第一部分展示当前用户已经上传了多少图片,通过Image的外键related_name进行查询;第二行就是一个小书签按钮,供用户拖到书签上,其中的内容通过include引入。
启动站点到/account/里边看一下。
现在把小书签拖过去还没有用,因为小书签里的地址 http://127.0.0.1:8000/static/js/bookmarklet.js还不存在,因此在images应用的目录下边建立static/js目录,然后建立bookmarklet.js。这里还记得把随书源代码中的CSS目录也copy到static中来。然后编写bookmarklet.js:
(function () {
let jquery_version = '3.3.1';
let site_url='http://127.0.0.1:8000/';
let static_url = site_url + 'static/';
let min_width = 100;
let min_height = 100;
function bookmarklet(msg){
// Here goes our bookmarklet code
}
// Check if jQuery is loaded
if(typeof window.jQuery !== 'undefined'){
bookmarklet();
}
else {
// check for conflicts
let conflict = typeof window.$ !== 'undefined';
let script = document.createElement('script');
script.src = '//ajax.googleapis.com/ajax/libs/jquery/' + jquery_version + '/jquery.min.js';
document.head.appendChild(script);
let attempts = 15;
(function(){
if(typeof window.jQuery === 'undefined'){
if(--attempts>0){
window.setTimeout(arguments.callee, 250)
}else {
alert("An error ocurred while loading jQuery")
}
}else {
bookmarklet()
}
})();
}
})();
现在又进入了JS时间(笑),这段代码先定义了几个变量,用于方便的修改jQuery的版本,站点相关的url,以及图片大小。然后的逻辑主要是导入jQuery,因此先检测jQuery是否存在,如果不存在就到Google的CDN上加载jQuery到head标签里。然后会间隔250毫秒重复去检测是否已经加载成功,一旦加载成功就执行bookmarklet函数。
现在来编写bookmarklet函数:
function bookmarklet(msg){
// load CSS
let css = jQuery('<link>');
css.attr({
rel:'stylesheet',
type:'text/css',
href:static_url + 'css/bookmarklet.css?r=' + Math.floor(Math.random()*99999999999999999999)
});
jQuery('head').append(css);
// load HTML
box_html = '<div id="bookmarklet"><a href="#" id="close">×</a><h1>Select an image to bookmark:</h1><div class="images"></div></div>';
jQuery('body').append(box_html);
// close event
jQuery('#boorkmarklet #close').click(function () {
jQuery("#bookmarklet").remove();
});
// find images and display them
jQuery.each(jQuery('img[src$="jpg"]'), function (index, image) {
if (jQuery(image).width() >= min_width && jQuery(image).height() >= min_height) {
let image_url = jQuery(image).attr('src');
jQuery('#bookmarklet .images').append('<a href="#"><img src="' + image_url + '"/></a>');
}
});
}
这段代码首先是装载CSS,用jQuery动态生成一个link元素,然后属性设置为我们网站里的那个CSS文件。然后加载HTML,使用一个box_html的HTML字符串,然后通过jQuery加载到body的尾部。之后给加载的元素绑定事件,让用户选择完图片后就清除新加入的元素。
最后一部分的功能是,用$.each方法遍历当前文档中的所有src以jpg结尾的img元素,然后逐个判断是否同时长和宽高于设置的最小值,是的话就把图片加入到最后插入的class类的div里。
在开始试验编写的功能之前,有些网站使用HTTPS协议,不会允许来自HTTP网站的小书签程序运行,因此必须将我们自己的网站弄成HTTPS出来,有一个工具Ngrok可以建立一个隧道将自己的本机变成HTTP和HTTPS向外提供服务。
下载下来解压之后得到一个exe文件,在命令行下运行:
ngrok http 8000
可以看到窗口里显示:
ngrok by @inconshreveable (Ctrl+C to quit)
Session Status online
Session Expires 7 hours, 58 minutes
Version 2.2.8
Region United States (us)
Web Interface http://127.0.0.1:4040
Forwarding http://d0de3ca5.ngrok.io -> localhost:8000
Forwarding https://d0de3ca5.ngrok.io -> localhost:8000
Connections ttl opn rt1 rt5 p50 p90
0 0 0.00 0.00 0.00 0.00
现在就有了一个公开域名可以同时使用http和https协议访问本机了。把这个网址加入到settings.py的ALLOWED_HOSTS里。启动django服务,来实验一下是否能从刚才的域名采用https访问网站。
结果发现真的可以,这样我们就有了一个使用HTTPS的公开域名,去将bookmarlet_launcher.ls里的scr修改为这个新的https域名,把bookmarklet.js里的site_url变量也修改为这个域名。
配置好HTTPS之后的dashboard.html页面如下:
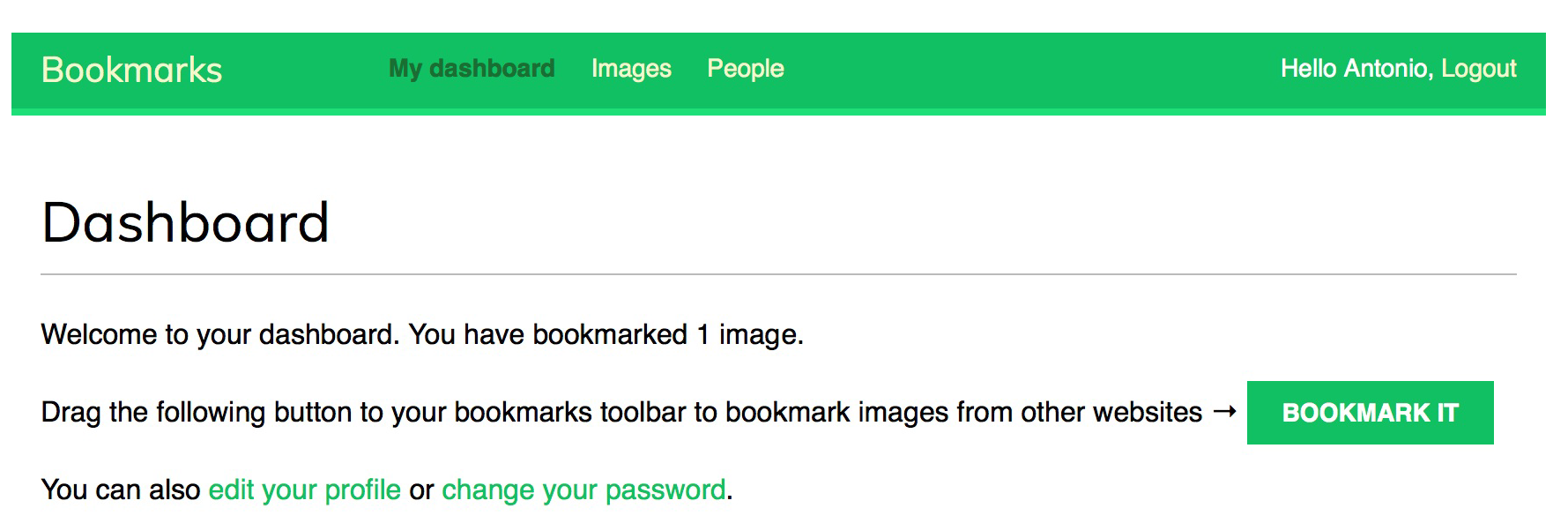
然后就访问新的HTTPS域名/account/login,任意用户登录之后,将那个BOOKMARTK IT的绿色按钮拖到书签栏里,然后就再找个网站,点击书签栏就会发现,页面左侧显示出了当前页面所有的大于100*100的JPG图像。
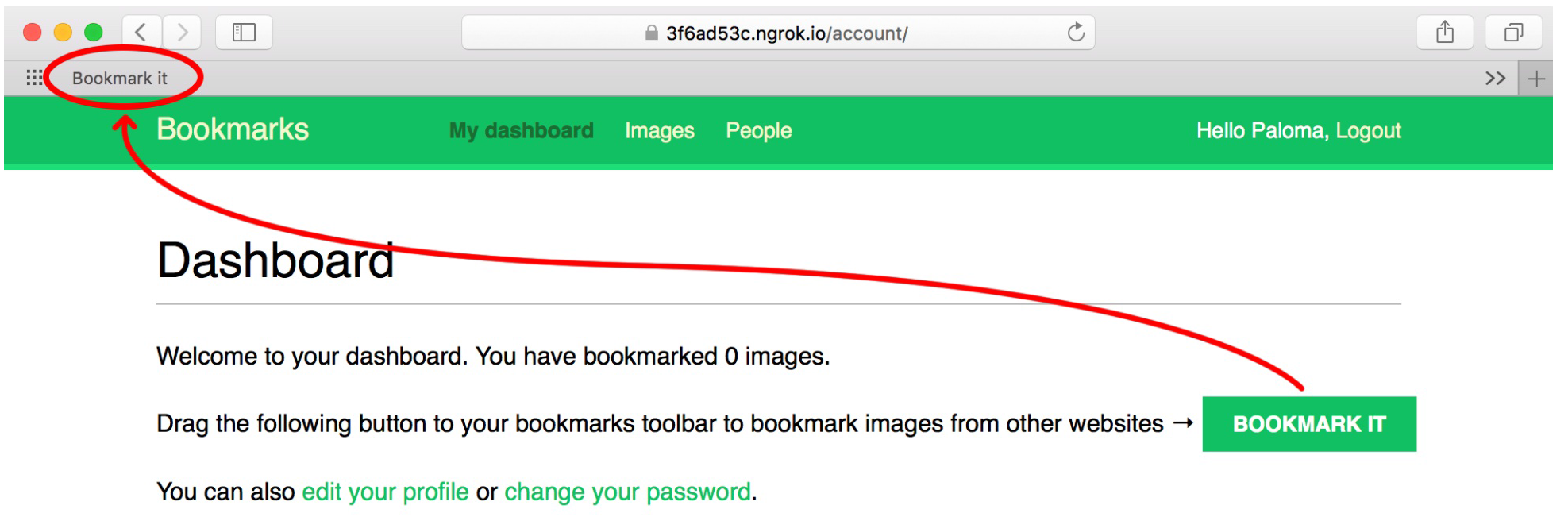
还剩下最后一步了,回想一下一开始我们编辑的视图是通过GET请求传递进来的,那么最后只需要将点击的那个图片的url和title拼接到一个GET请求上发回给我们的网站就可以了。继续编写bookmarklet函数:
// when an image is selected open URL with it
jQuery('#bookmarklet .images a').click(function(e){
let selected_image = jQuery(this).children('img').attr('src');
// hide bookmarklet
jQuery('#bookmarklet').hide();
// open new window to submit the image
window.open(site_url +'images/create/?url='
+ encodeURIComponent(selected_image)
+ '&title='
+ encodeURIComponent(jQuery('title').text()),
'_blank');
});
这个函数为点击图片绑定了事件,让selected_img的值为图片URL,然后隐藏这个框体。之后打开一个新页面,将之前我们的HTTPS网站加上配好的URL images/create/,之后加上GET请求的参数 ?url=用JS处理过的URI&title=JS拿到的当前页面的title值。
经过试验,确实可以通过书签很方便的将图片加入到自己的站点中来。
小书签程序在第三方网站上工作的示例如下:
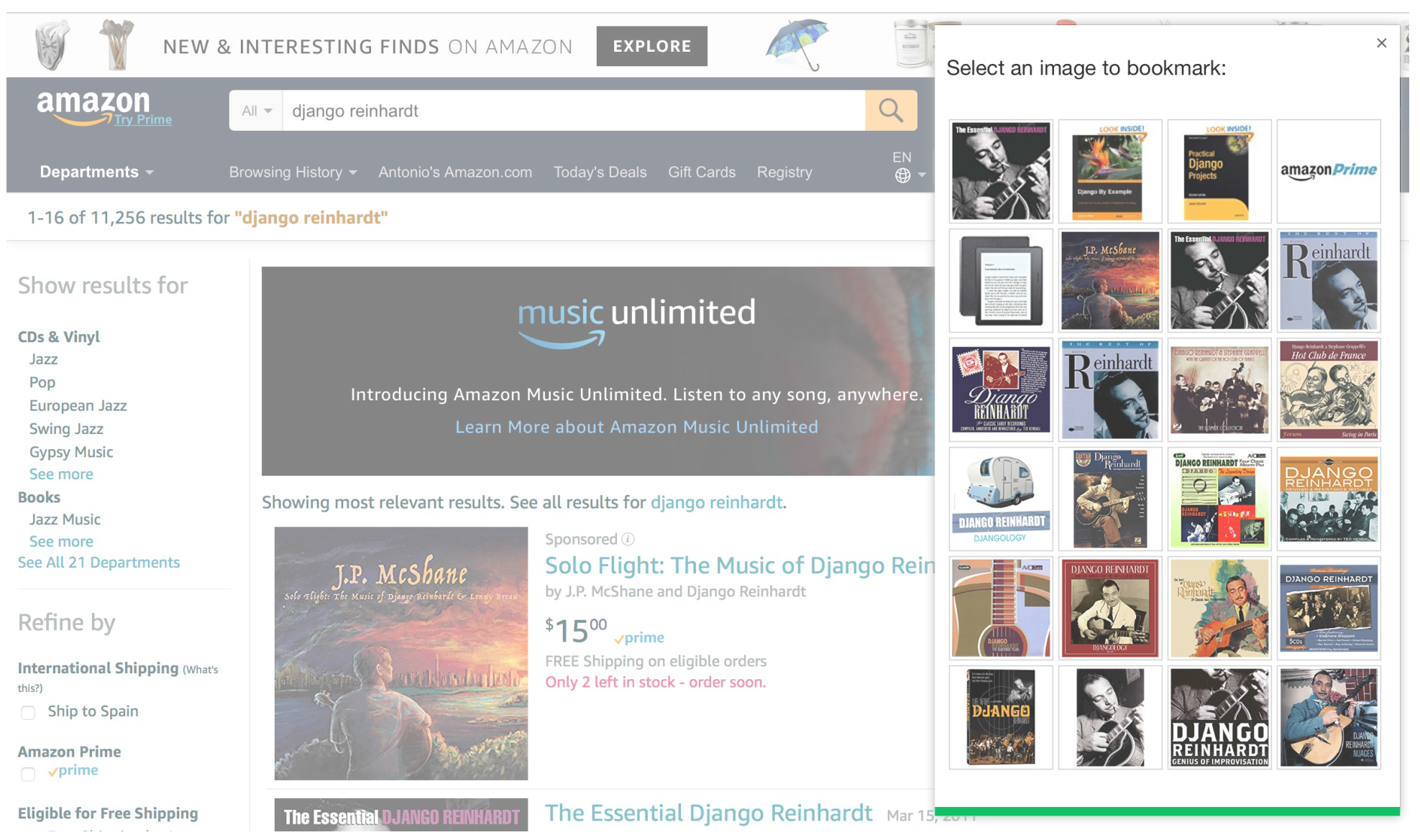
图片详情页与缩略图功能
刚才做完了外部内容分享并且保存至本机的功能,暂时不去动了。现在显然很迫切的需求就是给用户一个管理自己图片的功能,否则只上传,连图片都无法查看和操作,就没什么意义了。
Image类已经有了,现在要做的就是用视图和模板来做一个给用户展示图片详情的功能。编辑views.py:
def image_detail(request, id, slug):
image = get_object_or_404(Image, id=id,slug=slug)
return render(request, 'images/image/detail.html',{'section':'images','image':image})
这个也很简单,目的是展示一幅图片所以使用了get_object_or_404,下边配置url
# images/urls.py
path('detail/<int:id>/<slug:slug>/', views.image_detail, name='detail'),
看到这里,写过博客项目的我们微微一笑,就知道肯定要写get_absolute_url按照这个格式返回图片的URL了。
# get_absolute_url in models.Image
from django.urls import reverse
def get_absolute_url(self):
return reverse('images:detail', args=[self.id, self.slug])
这里多说一下,在django 2里,除了在include url的时候用namespace关键字参数指定命名空间之外,还可以在urls.py里写上app_name = 'namespace' 来设置命名空间,而APP默认有一个同名的命名空间。通过命名空间加名称可以找到想要的url,如果name是唯一的,直接通过name也可以找到。
get_absolute_url是很多情况下为了取得当前对象URL,其他程序会去默认调用的方法,因此一定要多写,多用。
之后就是建立模板了:
{#/templates/images/image/detail.html#}
{% extends 'base.html' %}
{% block title %}
{{ image.title }}
{% endblock %}
{% block content %}
<h1>{{ image.title }}</h1>
<img src="{{ image.image.url }}" class="image-detail">
{% with total_likes=image.users_like.count %}
<div class="image-info">
<div>
<span class="count">
{{ total_likes }} like{{ total_likes|pluralize }}
</span>
</div>
{{ image.description|linebreaks }}
</div>
<div class="image-likes">
{% for user in image.users_like.all %}
<div>
<img src="{{ user.profile.photo.url }}">
<p>{{ user.first_name }}</p>
</div>
{% empty %}
Nobody likes this image yet.
{% endfor %}
</div>
{% endwith %}
{% endblock %}
这里的逻辑也很简单,先展示图片,然后展示所有喜欢这个图片的用户。用with是为了暂时保存查询结果,避免反复查询数据库。
这里还有一个要解释的就是 image.image.url 和 user.profile.photo.url,这两个url不是Image类中的url字段,而是在定义Imagefield时候upload_to的路径名称。
这个时候有的图片可以正常保存,有的会报Noreservematch错误,分析原因,其实是作者有一个小疏忽。因为在Image类重写的save方法里,只把title赋给了slug,不能保证slug字段一定能够被path自动使用的正则匹配到,这里就用django内置的Slugify来处理一下即可:
# 修改 models.Image的save方法
from django.template.defaultfilters import slugify
def save(self, *args, **kwargs):
if not self.slug:
self.slug = slugify(self.title)
super(Image, self).save(*args, **kwargs)
这样slug就正确了。每次导入图片之后,会自动跳到这个图片的详情页面,还能显示谁喜欢了这张图片。
图片详情页的示例如下:
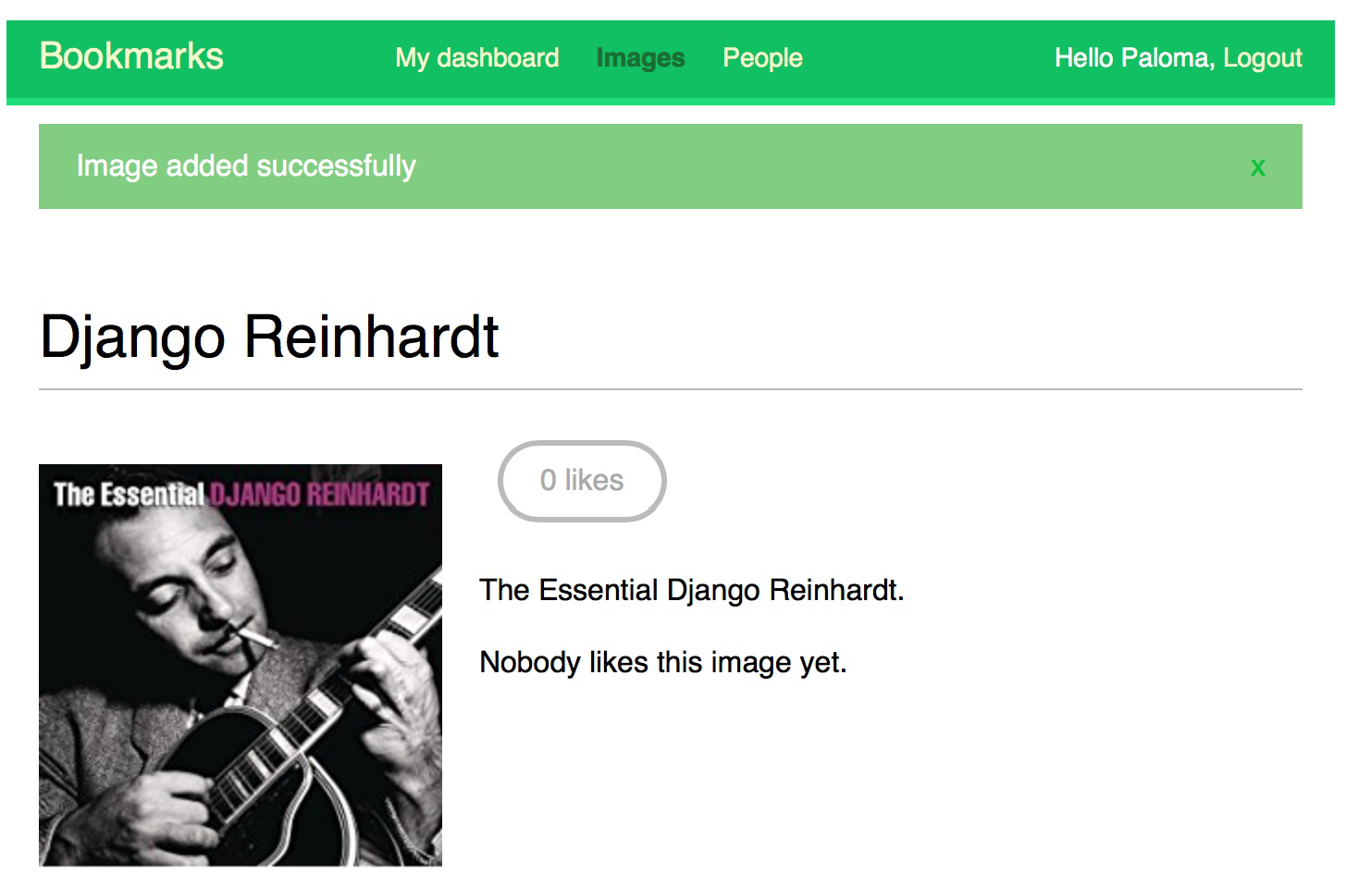
在做完了图片分享的跳转网站之后,很显然还需要做一个图片列表页给用户进行管理。由于用户上传过来的图片很可能比较大,而且分辨率各不相同,如果每次都按照原尺寸传输图片,速度较慢。
常用的解决方案就是显示缩略图,然后统一在页面上显示一个固定的大小,这里使用一个第三方库 sorl-thumbnail 来生成缩略图。
pip install sorl-thumbnail==12.4.1
# settings.py
INSTALLED_APPS = [
# ...
'sorl.thumbnail',
]
之后按惯例migrate,看到生成了一个新表。
这个模块的提供了一个新的模板标签{% thumbnail %}供在模板内显示缩略图,和一个基于Imagefield自定义的图片字段,用于在模型内设置缩略图字段。这两种方式都可以显示缩略图。
我们来采取模板标签的方法。先在detail.html页面中实验一下:
{% load thumbnail %}
{% block content %}
<h1>{{ image.title }}</h1>
{% thumbnail image.image '300' as im %}
<a href="{{ image.image.url }}"><img src="{{ im.url }}" class="image-detail"></a>
{% endthumbnail %}
...
{% endblock %}
通过之前提供的测试链接进来然后保存,通过浏览器的开发功能,可以看到生成了一个300*368大小的缩略图,放在了media/cache/目录下边。
这个插件还可以使用很多算法生成各种缩略图,具体文档可以看这里。值得一提的是如果生成不了,在settings.py里写一行 THUMBNAIL_DEBUG=True就可以让插件显示debug信息。
今后在自己开发的网站中,对于要向用户展示内容的图片,都应该使用缩略图。
使用AJAX
这是本章的第二个大内容。AJAX对于有基础的我们不再赘述了。有兴趣的读者可以看本站在Django中使用jQuery发送AJAX请求和使用原生JS发送AJAX请求的方法。
这里要实现的功能,就是用户在图片详情页点击喜欢和不喜欢。之前你可能已经注意到了,image_detail视图并没有使用@login_required装饰器,这是为了让所有用户都可以看到别人上传的图片然后来点赞。
点赞和取消赞是一个经常进行的动作,没有必要多次重载这个页面,这种只更新页面中的一小部分的功能,都可以用AJAX来实现。
编写视图
每个AJAX功能,都需要一个后台的视图来处理,所以需要在images的views.py中编写一个新的视图:
from django.http import JsonResponse
from django.views.decorators.http import require_POST
@login_required
@require_POST
def image_like(request):
image_id = request.POST.get('id')
action = request.POST.get('action')
if image_id and action:
try:
image = Image.objects.get(id=image_id)
if action == "like":
image.users_like.add(request.user)
else:
image.users_like.remove(request.user)
return JsonResponse({'status': 'ok'})
except:
pass
return JsonResponse({'status': 'ko'})
这里要解释几点:
- 导入了 JsonResponse,作用是把一串字符串格式化成JSON格式,返回给前端。AJAX一般都用来发送和接收JSON格式的字符串。
- require_POST是一个装饰器,限制视图只接受POST请求,比自己写判断要方便一些
- 前端我们用AJAX准备发过来两个东西,一个是当前图片的id,一个是当前的动作,其中动作打算发的是like和unlike
- 视图的其余逻辑很简单,如果一个用户点赞,就在Image类里多对多关系里增加这个用户,如果点了不喜欢,就去掉这个用户。
- 最后根据操作成功与否,返回ok或者ko。
- 多说一下的就是多对多关系的字段更新,有add,remove和clear三个方法,clear是清除该行数据的所有多对多关系。
通过后端的逻辑,我们就可以推断一下前端的逻辑:
- 一个用户打开图片详情页,如果他之前没有喜欢过这个图片,那么应该给他展示一个点喜欢的按钮,只要点了这个按钮,就会发送AJAX的like到后端去。如果他已经喜欢过了这个图片,那么显示一个取消喜欢的按钮,只要点了这个按钮,就发送AJAX请求到后端。
- 这个时候AJAX根据成功或者失败会返回不同的两个字符串,前端根据这个结果,相应的修改页面。如果成功了,就把原来的按钮变更另外一个按钮,如果失败,就显示错误信息但不修改按钮。
搞清楚了逻辑,下边来修改images/urls.py:
path('like/', views.image_like, name='like'),
这个path就是用来接受AJAX请求的地址。
编写前端页面
这里我们还会解决几个小问题:
- 页面内导入jQuery
- 页面内增加JS代码
- 页面内处理AJAX请求头增加CSRF
- 修改页面元素的内容
前端页面打算使用jQuery来发送请求,所以需要引入jQuery,可见学后端也必须精通前端是多么的重要。
修改base.html,在body标签内的最下边加上这些内容:
<script src="https://cdn.bootcss.com/jquery/3.3.1/jquery.min.js"></script>
<script>
$(document).ready(function () {
{% block domready %}
{% endblock %}
});
</script>
原书是用了googleCDN的jQuery,这里为了方便,采用了国内bootCDN的jQuery。之后下边代码用了ready函数内写了一个块,用于在DOM加载完毕的时候运行其中的代码。
接下来的一个问题是处理CSRF,由于后端我们接受的是POST请求,为了安全起见不可能去关闭CSRF中间件,所以需要jQuery发送请求时将CSRF信息一起发送过来。为此,常用的做法是在页面上埋一个CSRF_TOKEN,然后通过jQuery拿到这个token,将其中的数据包含在请求中一起发送。
书里的方法更加硬核一些,找了一个依赖于jQuery的第三方库JS.cookie,从cookie中取CSRF。这是因为只要启用了CSRF中间件,每次cookie中都会有CSRF数据。由于这段代码也是每次必须执行的,所以直接写在base.html中:
{#在导入jQuery后增加#}
<script src="https://cdn.bootcss.com/js-cookie/latest/js.cookie.min.js"></script>
<script>
let csrftoken = Cookies.get('csrftoken');
function csrfSafeMethon(method) {
// these HTTP methods do not require CSRF protection
return (/^(GET|HEAD|OPTIONS|TRACE)$/.test(method));
}
$.ajaxSetup({
beforeSend: function (xhr, settings) {
if (!csrfSafeMethon(settings.type) && !this.crossDomain) {
xhr.setRequestHeader("X-CSRFToken", csrftoken);
}
}
});
这里解释一下几个要点:
- 首先导入第三方库js-cookie,为了方便依然从国内BootCDN导入,js-cookie的源码地址。
- 通过Cookies.get方法拿到csrftoken 的值
- 建立了一个函数使用正则验证去测试HTTP请求,一般GET,HEAD,OPTIONS和TRACE请求无需使用CSRF
- 调用jQuery.ajaxSetup来对ajax做全局设置。
- AJAX设置中的beforesend设置了一个回调函数,第一个参数一定是XHR对象,第二个就是settings,从中可以取得HTTP的请求类型,只要不属于这些类型,就给XHR的请求头设置上CSRF键值对。
- 当然,还有很多方法可以设置请求头,在发送的时候使用beforesend和header属性都可以。
这样只要在点赞的时候发送AJAX的POST请求,其预先都设置好了请求头中包含CSRF信息。剩下的核心问题就是编写前端页面与发送AJAX请求相关的部分了:
修改detail.html页面,有几个地方需要修改:
1 把 {% with total_likes=image.users_like.count %} 这一行修改成:
{% with total_likes=image.users_like.count users_like=image.users_like.all %}
2 修改CSS类为image-info的div标签内的内容为:
<div class="image-info">
<div>
<span class="count">
<span class="total">{{ total_likes }}</span> like{{ total_likes|pluralize }}
</span>
<a href="#" data-id="{{ image.id }}" data-action="{% if request.user in users_like %}un{% endif %}like"
class="like button">
{% if request.user not in users_like %}
Like
{% else %}
Unlike
{% endif %}
</a>
</div>
{{ image.description|linebreaks }}
</div>
页面内的逻辑是:
- 新引入users_like变量保存所有喜欢该图片的用户,然后检测当前登录用户是不是在users_like中。
- 定义一个外观为按钮的A标签,其中有两个符合HTML5标准的自定义数据属性data-id和data-action,其中data-action的内容和A标签的文本属性根据第一条逻辑的结果而变化。
剩下的工作就交给前端代码了,AJAX做的工作已经很明显了,就是发送A标签的自定义数据属性,然后根据返回的结果,来更新A标签和页面内人数相关的内容。在detail.html里增加一段:
{% block domready %}
$('a.like').click(function (e) {
e.preventDefault();
$.post('{% url 'images:like' %}',
{
id: $(this).data('id'),
action: $(this).data('action'),
},
function (data) {
if (data['status'] === 'ok') {
let previous_action = $('a.like').data('action');
//toggle data-action
$('a.like').data('action', previous_action === 'like' ? 'unlike' : 'like');
//toggle link text
$('a.like').text(previous_action === 'like' ? 'Unlike' : 'Like');
//update total_likes
let previous_likes = parseInt($('span.count.total').text());
$('span.count.total').text(previous_action === 'like' ? previous_likes + 1 : previous_likes - 1);
}
}
);
});
{% endblock %}
这段代码说实在写的挺简单粗暴:
- 首先是给按钮绑定事件,事件里先停止按钮的默认功能,然后使用jQuery.post方法向反向解析的 'images:like' URL发送POST AJAX请求,请求内容就是通过data取到的自定义属性id和action
- 回调函数是匿名函数function(data),后边的逻辑判断很简单,就是返回数据的status为OK的时候,先拿到原来的A标签的action和内容,如果是unlike就变like,如果是like就变unlike
- 最后还要处理人数,这个也很简单,如果原来是like就加1,原来是unlike就减1。
为什么说简单粗暴,是因为点赞之后处理人数增加或者减少1的逻辑太过于粗暴,由于可以多用户登录,每个用户点过赞以后,未必只会变动1,完善的处理应该是每次点赞之后,后端应该返回实际当前喜欢的人数以及这些人的列表,然后再去填充相关的页面。这里估计作者也是为了简化一些处理,让用户立竿见影的看到结果吧。
现在可以到detail页面看一看效果了。可以手工增加赞了。
不过现在还有一个问题是,图片详情页面添加了多对多关系的时候,一刷新就提示一个The 'photo' attribute has no file associated with it.错误,这个估计是作者在这里没有讲清楚,因为detail.html 的页面用了user.profile.photo.url,但没有上传用户头像所致。在管理后台给每个用户上几个头像,再任意按照生成detail URL的方式访问任意详情图片页,就不会报错了。直接修改多对多的关系再查看这张表,就能发现显示出同样喜欢了这张图的用户头像和名称。这里如果要完善的话,应该判断用户是否上传头像,如果没有就用默认头像代替。
点击变化的示例如下:

自定义装饰器限制AJAX视图的使用
随着网站功能的增多,问题是一个接一个的出现。思考一下接受AJAX请求的后端,只是一个普通的处理POST请求和返回JSON字符串的后端。一般来说,需要明确的区分普通的后端与AJAX的后端。Django里对于request对象内置了一个.is_ajax()方法来判断视图接受的请求是否是一个AJAX请求(AJAX请求是一个XMLHttpRequest,有着特殊的报头HTTP_X_REQUESTED_WITH HTTP)
为了实现这个功能,我们就自行编写一个装饰器,用来让AJAX视图只接受AJAX请求,相信装饰器对于我们已经不陌生了。我们的装饰器打算用于任何一个视图,因此就在项目目录里建立一个叫common的包(带有__init__.py)的目录,下边建立一个decorators.py,编写其中的内容:
from django.http import HttpResponseBadRequest
def ajax_required(func):
def wrap(request, *args, **kwargs):
if not request.is_ajax():
return HttpResponseBadRequest()
else:
return func(request, *args, **kwargs)
wrap.__doc__ = func.__doc__
wrap.__name__ = func.__name__
return wrap
这里导入了HttpResponseBadRequest,这个的意思是返回一个400错误。如果是AJAX请求,则原来视图的功能正常执行。
想使用装饰器,就在views.py里像导入包然后像其他装饰器一样使用即可:
from common.decorators import ajax_required
@ajax_required
@login_required
@require_POST
def image_like(request):
......
之后试试直接访问:/images/like/,得到的是一个400错误。之前直接访问,得到的是一个405错误。
建立图片列表页并且使用AJAX分页
AJAX分页实现的一个功能是,当页面滚动到底部的时候,就会继续去发送请求拿到新的数据。我们准备建立一个新页面,用于展示当前用户所有上传的图片,但是只动态加载其中的一部分,当用户向下滚动的时候,会显示其他的图片。当达到预先设置好的最大值的时候,才算完整的一页。
先来写视图,这次依然用到内置的分页器:
@login_required
def image_list(request):
images = Image.objects.all()
paginator = Paginator(images, 8)
page = request.GET.get('page')
try:
images = paginator.page(page)
except PageNotAnInteger:
images = paginator.page(1)
except EmptyPage:
# 如果是AJAX发送的分页请求,空白页就只返回空字符串,即什么也不做
if request.is_ajax():
return HttpResponse('')
images = paginator.page(paginator.num_pages)
# 如果是AJAX请求,向下滚动的时候页数加了1,就再传页数加1的页面进到页面上渲染。
if request.is_ajax():
return render(request,
'images/image/list_ajax.html',
{'section': 'images', 'images': images})
return render(request, 'images/image/list.html', {'section': 'images', 'images': images})
视图的逻辑比较简单,按照8个图片一页,滚动的时候触发事件,设置了几个变量防止反复提交请求和返回空白页(分页已经到最后一页)块就不再发送AJAX请求,这里唯一要注意的就是,如果是普通请求超出了范围,那么就返回最后一页,如果是AJAX请求超出了范围,就意味着到了页面底部,那么就返回空字符串,什么也不干。其他情况下对于普通请求和AJAX请求都一视同仁。
但是下边为了实现滚动的要求,采用了一些小技巧,对于AJAX请求我们来渲染list_ajax.html,对于普通请求渲染list.html,但是其中包含list_ajax.html。现在先把URL配置好:
path('', views.image_list, name='list'),
通过URL可以看出,我们把图片列表页作为images/的默认页面。
之后先来编写list_ajax.html:
{% load thumbnail %}
{% for image in images %}
<div class="image">
<a href="{{ image.get_absolute_url }}">
{% thumbnail image.image "300x300" crop="100%" as im %}
<a href="{{ image.get_absolute_url }}">
<img src="{{ im.url }}">
</a>
{% endthumbnail %}
</a>
<div class="info">
<a href="{{ image.get_absolute_url }}" class="title">
{{ image.title }}
</a>
</div>
</div>
{% endfor %}
这个页面的逻辑比较简单,就是拿到当前的image然后挨个展示。
再编写list.html:
{% extends 'base.html' %}
{% block title %}
Images bookmarked
{% endblock %}
{% block content %}
<h1>Images bookmarked</h1>
<div id="image-list">
{% include 'images/image/list_ajax.html' %}
</div>
{% endblock %}
这个页面包含了ajax请求展示的页面,但是关键是在于其中的JS代码,还记得我们在base.html里定义了domready 这个块专门用于执行DOM加载完毕的代码,现在继续在list.html中编写JS代码:
let page = 1;
let empty_page = false;
let block_request = false;
$(window).scroll(
function () {
let margin = $(document).height() - $(window).height() - 200;
if ($(window).scrollTop() > margin && empty_page === false && block_request === false) {
block_request = true;
page += 1;
$.get("?page=" + page, function (data) {
if (data === "") {
empty_page = true;
}
else {
block_request = false;
$('#image-list').append(data)
}
});
}
}
);
这段JS代码是用了滚动事件,设置了一个margin变量为页面实际的高(超出当前窗口也算上)减去-整个视口的高再减去200。向下滑动距离底部小于200像素的时候的时候就会触发这个事件。同时设置回调函数,如果还能拿到新页面,则阻止请求的函数再改成false。回调函数里的data就是HTML字节流,直接添加在#image-list的标签之内即可。
最后还有一点要修改的,就是把base.html里的Images链接修改成"images:list"即可。
还有一个地方是,当分页的时候console 里会提示,Image的查询没有排序,进行分页可能会造成不一致的结果,这个在image_list的视图中增加一个按照create排序即可。created字段在建立模型的时候已经设置过索引
还有一点要说的就是我们用了同一个视图处理ajax请求和普通请求,所以ajax不用设置目标url,只需要直接发送即可,默认就是当前页面的URL。例子中的$,get方法的第一个参数直接使用了GET请求的附加数据,AJAX实际发送到的URL地址就是当前页面地址加上后边的附加参数。
带有动态加载功能的图片列表页的示例如下:
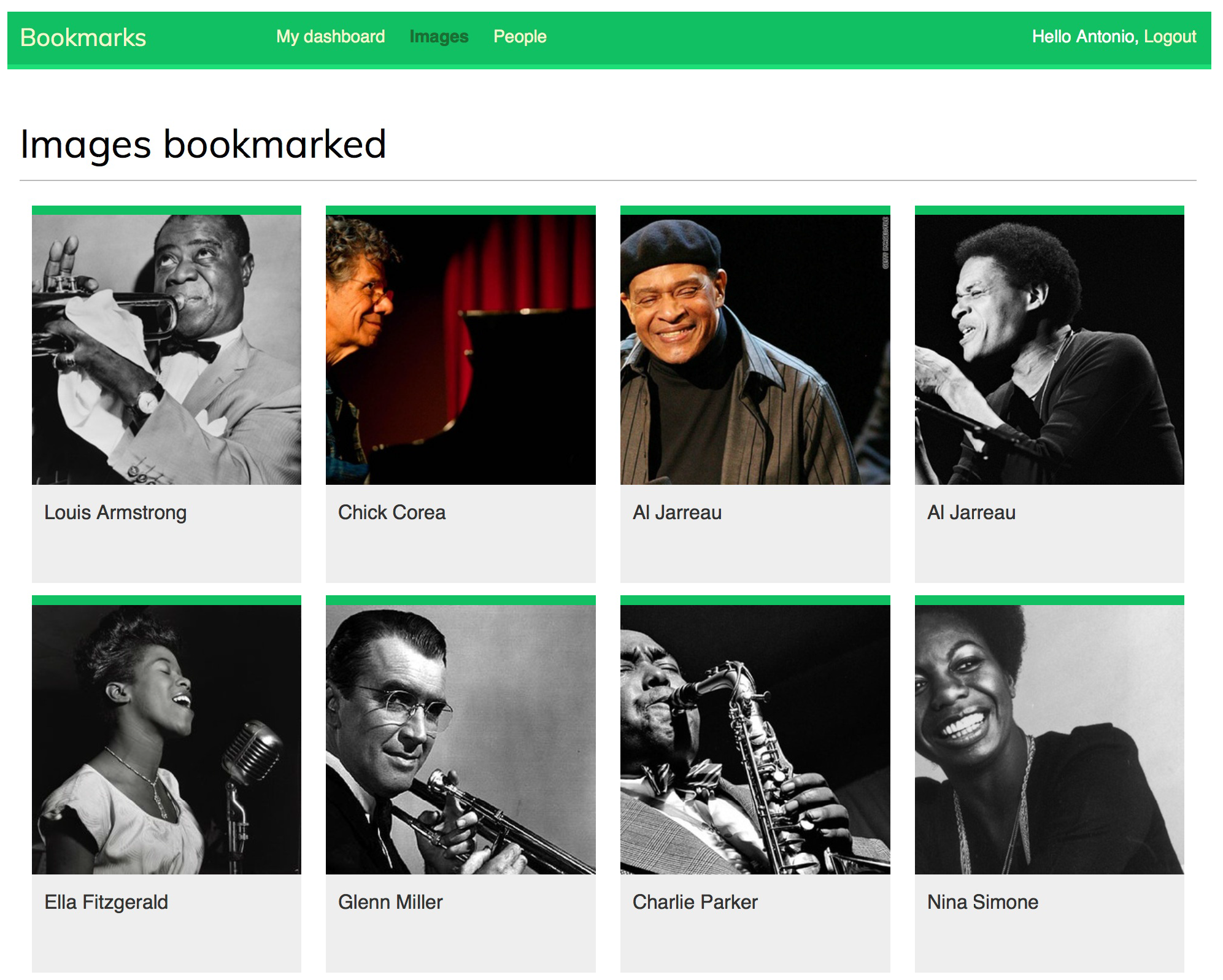
总结
这一章的开发难度比起上一个项目有着明显的提升,而且使用了前后端的的各种技术和第三方插件:
- 建立包含有文件字段的数据类
- 重新model和form类的save方法,用来完善一些字段
- form.save()方法返回model类的对象。而Imagefield也有save方法和.url属性
- 小书签的JS启动器编写
- 使用JS动态加载CSS和JS文件
- sorl模块生成缩略图
- 使用AJAX发送请求和更新页面
- 自定义装饰器控制视图只能接受AJAX请求
- 滚动加载图片的技巧:使用AJAX从分页器中获得数据。