
Django基础部分
欢迎来到Django 2 by example的教程。你看到的是目前全网唯一翻译该书的教程。为了简便,与Django基础安装的部分在此略过,直接从该书的实质性部分讲起。 查看Django版本:
import django
django.get_version()
虽然书里的django版本是2.0.5,但是正好2.1发布了,就直接安装2.1版本。 建立网站
django-admin startproject mysite
可以建立不同的 settings.py来使用不同的配置文件。
python manage.py runserver 127.0.0.1:8001 --settings=mysite.settings
这里可以找到在生产环境下配置Django为WSGI应用程序的具体内容。
Django的设置
关于settings.py的官方文档地址:这里。目前先来介绍一下这个文件的组成部分和功能。 打开settings.py进行一些设置:
DEBUG=True,生产环境设置为false,不会打印普通日志信息和错误信息。
ALLOWED_HOSTS当Debug启用的时候无效。不处于Debug模式的时候,必须在此设置主机地址,即Django服务器的地址。
INSTALLED_APPS是每个项目的核心,列出了每个项目所使用的app也就是应用,默认的如下:
django.contrib.admin 是管理站点
django.contrib.auth 认证模块
django.contrib.contenttypes 处理contenttypes,与ORM模型有关
django.contrib.sessions 处理session
django.contrib.messages 处理消息
django.contrib.staticfiles 处理静态文件
MIDDLEWARE是中间件列表,中间件就是Django,很重要。
ROOT_URLCONF 写明了你的站点的根URL patterns对应的文件。
DATABASE 数据库,默认是内置的SQLite3,必须始终有一个default数据库,可以添加其他自定义名称的数据库用于使用。
LANGUAGE_CODE 语言代码
USE_TZ = True 告诉Django是否启用时区支持,如果通过manage.py建立站点,会默认设置为True
Projects and applications
在学习Django的过程中,会反复的看到这两个单词,项目指的就是整个Django运行的网站,而applications指的就是一组Model+Views+Templates+URLs 建立app:
python manage.py startapp blog
在网站根目录下边建立一个叫blog的目录,里边有一系列文件:
admin.py 用于将模型注册到该文件中,以便在Django的管理后台查看。
apps.py 包含当前应用的主要设置
migrations文件夹 这个目录包含应用的数据移植过程追踪,Django用这个目录追踪你的数据模型models的变化然后和数据库同步。
models.py 当前应用的数据模型,所有与model有关的内容最好放在这里。所有的应用必须有这个文件。
test.py 为应用增加测试的地方
views.py 应用的业务逻辑部分,每一个view接受一个HTTP请求,处理,然后返回一个响应。
设计博客的数据模式
后端开发,针对一个应用,必须先设计数据模式,有了数据模式就可以确定models.py的内容,之后才能用逻辑代码。 所有的model 都是 django.db.models.Model的子类。类的每一个属性代表一个数据字段。在models.py内创建类,然后Django提供了一套API用于操作数据。 博客的核心内容就是一篇篇文章(POSTS)。定义一个Post类:
from django.db import models
from django.utils import timezone
from django.contrib.auth.models import User
class Post(models.Model):
STATUS_CHOICES = (
('draft', 'Draft'),
('published', 'Published')
)
title = models.CharField(max_length=250)
slug = models.SlugField(max_length=250, unique_for_date='publish')
author = models.ForeignKey(
User,
on_delete=models.CASCADE,
related_name='blog_posts')
body = models.TextField()
publish = models.DateTimeField(default=timezone.now())
created = models.DateTimeField(auto_now_add=True)
updated = models.DateTimeField(auto_now=True)
status = models.CharField(
max_length=10,
choices=STATUS_CHOICES,
default='draft')
class Meta:
ordering = ('-publish',)
def __str__(self):
return self.title
简单解释如下:
title属性(字段名称)对应CharField类型,在SQL里是Varchar
slug字段是打算用于URL的,slug是一个短的字符串,只能包含字母,数字,下划线和减号。用slug字段一般是构成优美的URL用,也方便搜索引擎搜索。其中的unique_for_date指的不允许两条记录的publish字段日期和title字段全都相同。具体看这里
author是一个外键,外键用于描述多对一关系,即多个posts可能有一个作者。这个意思就是说每个文章有一个作者,一个作者可以写多个文章。这里的User使用了Django自己的用户模块,这个User类就对应刚才Django初始化migrate的时候生成的其中的用户表。on_delete设置为CASCADE表示如果删除了User表里的用户,就把该作者对应的文章全部干掉。这并不是Django的特殊操作,而是数据库的标准操作。具体看这里。注意是外键连到的表内容被删除,不是删除自己。设置related_name这个的意思是:现在在当前Post类查作者就用author属性,如果要从关联的User表查文章,就用related_name指定的名称。注意,这个名字在当前类是没用的,对User类才生效。
body 对应一个文本域,到数据库里变成一个TEXT类型。
publish,即发布文章的时间。Django模型里的所有时间类型,可以使用Python自己的datetime类,也可以用Django的timezone类型,可以把timezone类型认为是带有时区的Python datetime.now方法。
created,这个表示建立文章(不一定发布)的最初时间,auto_now_add表示当建立一行数据的时候,自动用建立数据的时间填充。填了之后就不再修改
updated,表示最后修改文章并且发布的时间,auto_now表示每次更新数据的时候,都会用当前的时间填充,这样就可以追踪最后一次的时间。
statues,这个字段表示POST的状态,使用了一个choices方法,所以这个字段的值只能够是给予的参数。choices用于页面上的选择框标签,需要先提供一个二维的二元元组,第一个元素表示存在数据库内真实的值,第二个表示页面上显示的具体内容。在浏览器页面上将显示第二个元素的值。
Meta类用于定义一些非字段的信息,这里是指定了排序是publish字段的逆序(字符串内加了一个减号)
__str__这个就是Python自己的类的功能了,不是Model类的功能了,表示如果打印对象(一行数据)的话显示标题(这行数据的title字段)
激活应用
编辑 settings.py 加上去一行:
'blog.apps.BlogConfig',
这样就将新的APP注册到Django里然后激活了。
在数据库中建立数据表
激活了新的应用之后,再执行migrate,就会把所有的app的模型变化都检测一遍然后写入到表里了。这里需要先makemigrations,再migrate: 执行后会在blog应用下的migrate目录里新增一个0001_initial.py的文件,实际就是将用户的表再进行了整理,比如添加了id 执行migrate命令之前先执行一下sqlmigrate,这个命令不会实际执行,会返回sql语句。可以看到在外键和slug(设置了unique)的字段还建立了索引。 可以看到表名并不是Post,而是加上了应用的名称,如果想要自定义,就在Meta类中指定db_table的值即可。 主键被自动创建了。默认的主键名称是id。 最后执行migrate命令建立数据表。建立之后如果对Post类有修改,要重新从makemigrations开始执行一遍。
为数据模型建立后台管理站点(administration site)
Django自带了一个管理站点,可以根据数据模型自动生成管理界面,只需要注册即可。 自带的管理站点功能启用需要在settings.py中的INSTALLED_APPS里边增加'django.contrib.admin',默认就用,不用更改。 要使用管理后台,需要先注册一个超级用户,使用manage.py来操作:
manage.py createsuperuser
输入用户名密码和邮件。 建立好超级用户之后,就可以从/admin/进管理后台了。 管理后台登录界面如下:  进去之后看到的Groups和Users是因为django.contrib.auth已经在其中注册过了。点击 User可以看到注册过的用户。注意我们的Post类还没有进来,而且Post类的外键author连到了这个User表上。 默认的管理后台首页如下:
进去之后看到的Groups和Users是因为django.contrib.auth已经在其中注册过了。点击 User可以看到注册过的用户。注意我们的Post类还没有进来,而且Post类的外键author连到了这个User表上。 默认的管理后台首页如下: 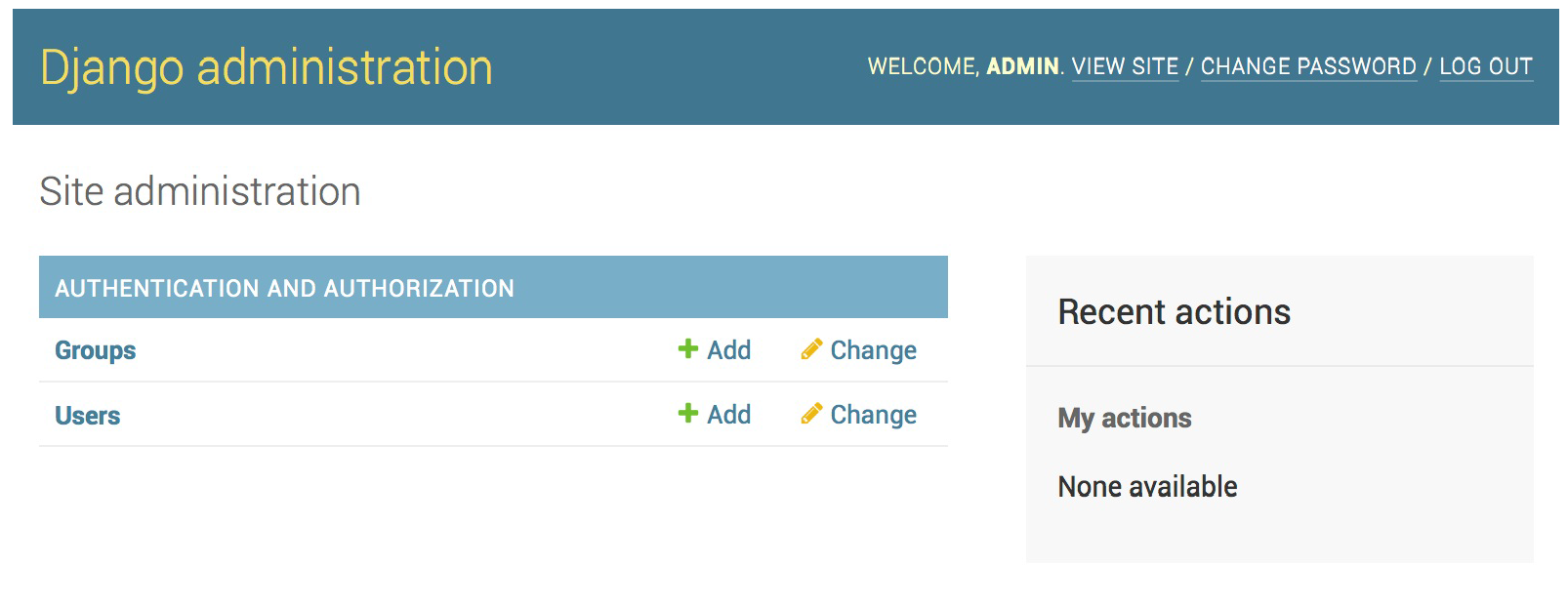
把Post类添加到管理后台中
这个在blog应用的admin.py里添加:
from django.contrib import admin
from .models import Post
admin.site.register(Post)
之后刷新页面,就可以看到出来了Post类,可以增删改查。这些字段的样式,是直接可以通过Django Form从Post类中生成的。后边会学。  现在先添加第一篇文章,点开Post后选右上角的ADD POST,界面如下:
现在先添加第一篇文章,点开Post后选右上角的ADD POST,界面如下: 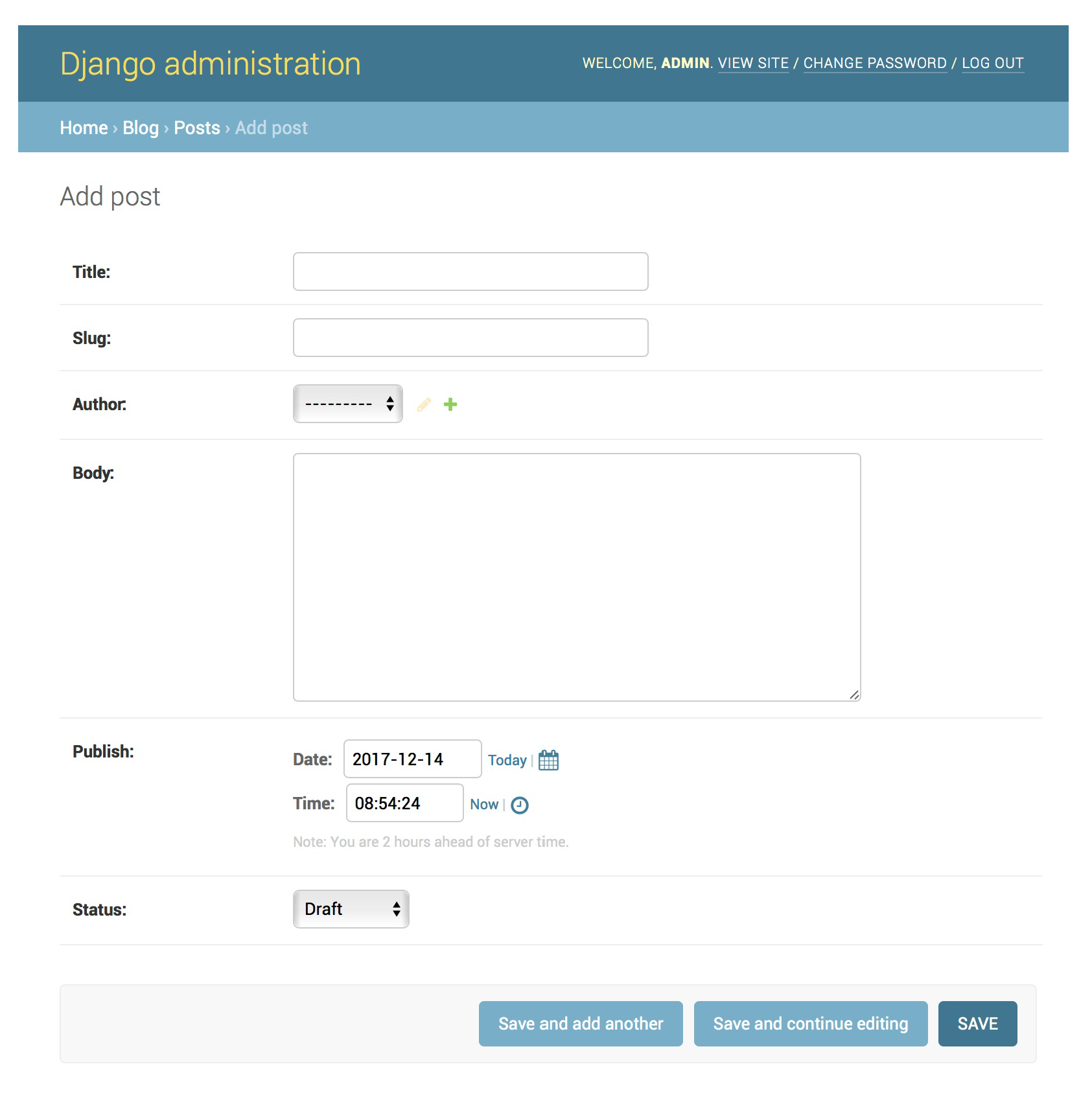 点击保存之后在Post中可以看到新添加的文章:
点击保存之后在Post中可以看到新添加的文章: 
个性化控制管理后台的显示
现在回到blog应用的admin.py,修改一下里边的内容:
@admin.register(Post)
class PostAdmin(admin.ModelAdmin):
list_display = ('title', 'slug', 'author', 'publish', 'status',)
list_filter = ('status', 'created', 'publish', 'author',)
search_fields = ('title', 'body',)
prepopulated_fields = {'slug': ('title',)}
raw_id_fields = ('author',)
date_hierarchy = 'publish'
ordering = ('status', 'publish',)
这个意思是说继承一个admin.ModelAdmin类,然后装饰这个类(装饰器的功能和之前直接用admin.site.register功能相同),参数是我们的Post,然后list_display属性表示展示那些字段。 其中很多参数,不如先刷新一下页面: 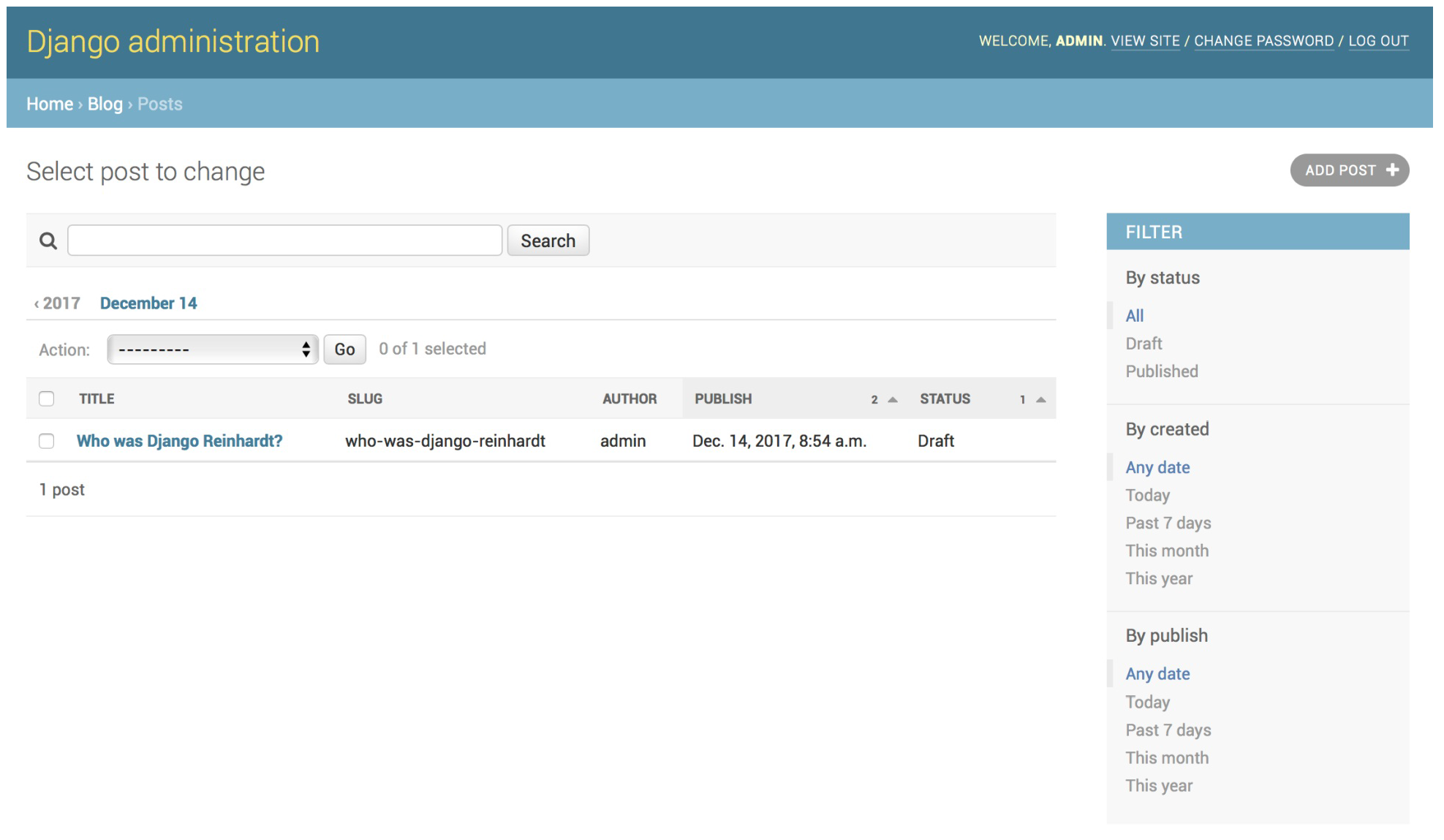
list_display是显示的字段
list_filter表示那些字段右边有个小三角可以用来筛选
出现了一个搜索框,因为定义了search_fields,可以搜标题和内容。
搜索框下边出现了按时间分类,这是因为定义了date_hierarchy
可以发现文章按status和publish排序了,这是因为定义了ordering
这个时候点开新增文章,可以发现也有变化,slug会根据标题来变化 作者那里显示id而不是名字了,但是下拉的时候依然可以选择名字。这是raw_id_fields的作用 后边还会学到很多扩展Django 自带的管理后台的方法。
操作数据模型,使用QuerySet查询
前边应该说都是静态的在准备数据,QuerySet搭配views就是实现网站与数据库交互的核心。 这里是django的model文档。 下边就又是到了增删改查的时间了。
增加数据行(Create)
python manage.py shell
这样就启动了带当前django 环境的 shell 之后来录入一段命令:
>>>from django.contrib.auth.models import User
>>>from blog.models import Post
>>>user = User.objects.get(username="lee0709")
>>>post = Post(title='Another post',slug='another-post',body='Post body',author = user)
>>>post.save()这段代码做的事情只从python来看,实际上是导入了两个类,然后取得了一个用户变量,最后用这个用户加一些字符实例化了一个post对象,然后执行了.save()方法。 然后刷新管理后台,可以发现,这一段代码的结果是添加了一篇新文章(数据库里的一行数据)。 再回头来一行行看:
get()从数据库中拿单独的一行数据时候使用,如果不存在,会报
DoesNotExist错误,如果超过1个,报MultipleObjectsReturn错误。这两个错误都是django里定义的,是查询的那个类的属性。数据表是类,我们实例化的对象,就是一行数据。然后用.save()方法,就是将该行数据写入数据库。
这里实例化对象和写入数据库是分开的,可以用create方法一次性完成该操作:
>>>Post.objects.create(title='One more post', slug='One more post', body='Post body', author=user)执行完之后可以发现又多了一条记录。
修改数据行(Update)
继续命令行
>>>post.title = 'New title'
>>>post.save()
这个时候的post,还指向刚才的那条数据,修改完之后save,发现标题更改了。其实save()方法就是用来做更新的,而新建更常用的是.create()方法
查找数据行(Retrieve)
这里就引入ORM了,ORM返回的是QuerySet也就是一组数据行,里边每一个都是一个数据类的实例。 现在比较简单的查询,就用all() 继续命令行:
>>>all_posts = Post.objects.all()
这里要注意的是,给Post.objects.all()赋给变量,还没有直接执行。QuerySet是惰性求值的,每次使用到的时候都会去求值。也就是说,赋给一个变量之后,不管之后对数据库增删改查了,只要使用该变量的地方,每次都会拿到新的结果。 all()方法有点太简单粗暴,用过数据库就知道还是得用其他查询方法,对应ORM里就是.filter()方法,里边加上字段名和值就可以了。 filter返回的是一个QuerySet,可以继续对其使用filter方法。
目前使用到的filter方法:
Post.objects.filter(publish_year=2017) 查某个字段符合条件
Post.objects.filter(publish__year=2017, author__username='admin') 这两个条件是and的关系,同时符合这两个条件
Post.objects.filter(publish__year=2017).filter(author__username='admin') 连续使用filter
有filter就有排除法:exclude(),从结果里去掉符合条件的数据行。
Post.objects.filter(publish__year=2017).exclude(title__startswith='Why')
取了数以后要排序咋办,用order_by方法
Post.objects.order_by('-title')
如果不指定order_by,对应字段会按照class Meta里的顺序列出。 前边这三个玩意 filter,exclude,order_by,都返回一个QuerySet,因此可以任意反复连用。
删除数据行(Delete)
选出来数据然后调用.delete()方法即可,注意之前说的CASCADE。删除被外键引用的数据,会把该数据通过外键对应的数据全部一起删除。
QuerySet何时会被求值:
使用QuerySet一个很重要的问题是要知道何时才会被求值,否则会导致取出的数据有问题。
第一次迭代QuerySet
切片的时候
pickle或者cache QuerySet的时候
调用repr()或者len()方法
显式调用list()方法
将其用在测试表达式中。比如bool,if,or,and等
基本上就是必须对表达式求值才能操作的情况下才会去求值,否则就一直惰性。
自定义模型管理器
类名后的.objects就是django自带的模型管理器,所有的ORM方法都是通过这个属性来操作的(数据类同时也是Python类,可以自定义任何方法)。还可以自定义这个管理器。 自定义模型管理器有两种方法,一是自行编写,二是修改默认的objects管理器。 先来看自行编写,模型管理器也是数据类,在blog的models.py里编写代码如下:
class PublishedManager(models.Manager):
def get_queryset(self):
return super(PublishedManager, self).get_queryset().filter(status='published')
class Post(models.Model):
objects = models.Manager() # The default manager
published = PublishedManager() # Our custom manager
原理很简单,超类的get_queryset()方法返回默认的QuerySet,继承超类重写方法,加上自定义的filter即可。然后在Post类里自定义一个属性叫published,指向自定义的新类。 再到命令行里实验一下:
Post.published.filter(title__startswith="New")
果然发现只从status是published的数据行中取了。而还可以改用objects管理器使用默认查询。
建立URL和视图函数
现在基础的查询数据和建立数据表结构知道了,这是后端的基础。之后就可以编写前后端交互的部分了,就是用视图函数处理HTTP请求,然后渲染对应的页面。这也是一个比较复杂的过程,分很多步讲。 首先,就是建立视图函数和分配URL以让HTTP请求找到对应的视图函数。
写两个视图函数
# blog应用的 views.py内编写:
from django.shortcuts import render, get_object_or_404
from .models import Post
def post_list(request):
posts = Post.published.all()
return render(request, 'blog/post/list.html', {'posts': posts})
建立了一个视图函数,用于接受HTTP请求,取得了所有已经发布的文章,然后渲染一个页面,传入其中的模板参数post的值为这个QuerySet 现在这个视图还无法工作,因为URL没有配置,页面也没有写。 凡是views.py里编写的至少带有一个参数的函数都是视图函数,这个参数可以起任意名字,但约定俗成是request,这个参数一定会被中间件传入HTTP请求作为值。 再写一个视图,这个视图函数有不止一个参数
def post_detail(request, year, month, day, post):
post = get_object_or_404(Post, slug=post, status="published", publish__year=year, publish__month=month,
publish__day=day)
return render(request, 'blog/post/detail.html', {'post': post})
单从名字和内容来看,这个视图函数是只取一行数据也就是一篇文章,然后渲染到另外一个页面上。还记得之前设置slug的时候有unique_for_date指向了publish字段,就说明通过年月日和slug一定可以找到唯一的一篇文章(或者找不到)。 get_object_or_404这个shortcut(快捷函数)就是用于去从ORM模型里按照指定的参数去拿数据,如果找不到,就返回一个404错误。
配置URL pattern
URL pattern本质上是一种映射关系,将所建立的网站的各个URL映射到视图函数上,让各个视图函数处理不同的URL。 一条URL pattern 由一个URL路径,一个视图函数和一个整个项目内通用的命名这个URL pattern的名称组成。Django按照代码编写的顺序匹配URL,匹配成功就不再匹配剩下的。 匹配成功之后,Django就会把HTTP请求以及其他的位置参数和关键字参数一起传给视图函数,其中第一个参数必定是HTTP请求,这也是为什么刚才编写的视图函数第一个函数都约定俗成叫做request 在blog应用下目录下边新建一个 urls.py 文件,然后里边写如下内容:
from django.urls import path
from . import views
app_name = 'blog'
urlpatterns = [
# post views
path('', views.post_list, name='post_list'),
path('<int:year>/<int:month>/<int:day>/<slug:post>/', views.post_detail, name='post_detail'),
]
终于到了Django 2 与Django 1 不同的地方了,就是urls pattern不再使用原来的urls,而是改用了path。一行行来看这个程序
app_name 指的是当前文件对应的app名称,也就是这个路由是为了哪个app服务的。
urlpatterns这个是固定的名称,是一个列表,每一行放一个URL pattern,组成就像上边所说。
第一个URL pattern没有任何内容(额外参数),指向 post_list 视图,第二个带了四个参数,这四个参数会和request一起传给 post_detail视图,这也是为什么视图带有五个参数。
非常重要的是这个url pattern的匹配方式,与原来Django 1代采用正则分组匹配获取额外参数的方式不同,Django 2 里更加方便,将所需要的每一个参数名和类型用尖括号包起来即可。其中类型是固定好的几个,看这里。比如如果匹配的URL是
/2017/09/13/DOS2,这个匹配的结果就会是year=2017,month=9,day=13,slug='DOS2'。如果URL进行了统一规划,则这种方式比正则匹配简单快捷。对于更加复杂的URL,如果想使用正则匹配,则就需要用 re_path方法来替代path方法,这个时候第一个位置的参数就像Django 1代一样是一个正则表达式,其匹配规则也和Django 1 一样。
编写完blog应用里的路由之后可以发现,第一个URL pattern 的路径匹配是空,好像不太对劲吧。实际上,前边说了当前文件的URL命名空间是blog,还是需要上一级路由把URL转发过来继续解析。所以还需要在站点根目录下边的urls.py(一级路由文件)里进行设置。 到mysite目录下编辑urls.py文件:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('blog/', include('blog.urls', namespace='blog')),
]
这里可以看到path的第三种用法,就是转发URL解析的结果。include的参数第一个是应用名.urls(也可以是别的文件名),之后的是命名空间,这个命名空间必须在整个项目里唯一。这句话的结果就是,将所有匹配'blog/'成功的URL转发到blog命名空间继续解析,存放进一步解析路径的文件是blog.urls(.py) 这里可以找到Django 2详细的URL命名空间的说明。
规范化数据模型的URL
在前边的路由里加入了命名空间,解析方式等一系列内容,设置了匹配规则,这个规则反过来想,同时也可以用于生成URL。那么针对每一篇文章,其实可以根据这个规则来生成该文章的URL。 传统的做法是给类添加一个自定义的get_absolute_url()方法来获取规范URL。这里来利用 reverse() 反向解析方法来编写这个方法用于获取URL,修改blog应用里的models.py:
from django.urls import reverse
class Post(models.Model):
def get_absolute_url(self):
return reverse('blog:post_detail', args=[self.publish.year,
self.publish.month,
self.publish.day,
self.slug])
通过看reverse的源码,就能发现这玩意最后是把带有绝对路径的视图函数的名称,分隔符,外加传入的所有参数拼成了一段URL,而且最后是调用了iri_to_uri函数(将一串unicode的iri转换为只包含ASCII字符的uri) 这样对每个对象(每篇文章)调用这个方法,就能够得到这篇文章的完整URL。
建立模板
之前准备了视图函数然后匹配了URL,也搞好了模型,现在就差最后一步,就是做页面展示。 在blog目录下建立templates目录,再建立blog目录,里边放base.html,再建立post目录里边放list.html和detail.html 模板表面上看是一堆HTML文件,但在其中加入各种控制渲染的东西,最终将HTML加上后端数据渲染成实际的HTTP字节流返回给浏览器。所以HTML文件对于Django来说叫做模板,是用于生成最终页面的模板。 模板可以继承,base.html就是打算用来继承的模板。list.html和detail.html都会继承base.html。 控制渲染东西叫做模板语言,由模板标签(template tags),模板变量(template variables),模板过滤器(template filters)组成:
template tags 控制渲染,即看到标签才渲染,没标签的地方就是原始HTML文件,长的像这样: {% tag %}
template variables 可认为是模板标签的一种特殊形式,即只是一个变量,渲染的时候只替换内容,长成这样:{{ variable }}。而其他模板标签还可以进行业务逻辑操作。
template filters 可认为是小函数,附加在模板变量上改变变量最终的结果。
关于模板语言的官方文档在此。和Django 1代比较类似。 好,下边编写模板base.html,准备用来展示内容了。
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>{% block title %}{% endblock %}</title>
<link rel="stylesheet" href="{% static "css/blog.css" %}">
</head>
<body>
<div id="content">
{% block content %}
{% endblock %}
</div>
<div id="sidebar">
<h2>My blog</h2>
<p>This is my blog.</p>
</div>
</body>
</html>
详细来看这段代码:
{% load static %} 表示导入由 django.contrib.staticfiles 应用提供的 static 模板标签,导入之后,在整个当前模板中都可以使用 {% static %} 标签来标识静态文件存放的位置。对于目前这个例子来说,会到当前应用 blog 下边的 static/ 目录里去找 blog.css文件。
还有两段 {% block %} {% endblock %} 这个表示名字叫做title和content的两个块。继承base.html的模板可以用指定的块替换其中的内容
母版做好了,继续编写list.html:
{% extends "blog/base.html" %}
{% block title %}My Blog{% endblock %}
{% block content %}
<h1>My Blog</h1>
{% for post in posts %}
<h2>
<a href="{{ post.get_absolute_url }}">
{{ post.title }}
</a>
</h2>
<p class="date">
Published {{ post.publish }} by {{ post.author }}
</p>
{{ post.body|truncatewords:30|linebreaks }}
{% endfor %}
{% endblock %}
这里也需要解释一下:
第一个{% extends %}表示继承母版base.html,相当于把母版所有的内容放到这个代码所在的地方。注意,在应用里的路径,默认都是以当前应用的根目录开始的。
{% block title %}My Blog{% endblock %} 这是一个块,名字就对应母版的那个块。注意,从这里开始,这些代码实际上是在HTML标签之外的,因为之前的部分就是母版全部的部分。这里开始之后的内容会被替换到母版中。
{% block content %}和对应的{% endblock %}之前的内容也是一个块要去替换母版,其中还有很多标签。
{% for post in posts %} 与{% endfor %} 之间是一对,这是循环,每次生成一个h2-a标签,链接就是刚才编写的拿到绝对路径的方法,内容就是标题。后边还有发布时间和作者。
还应用了两个filter,一个是截断30个字符,linebreaks用于显示HTML的换行,filter可以任意连用,每个都在上一个的结果上生效。
好了,多说无用,现在可以起项目了,运行网站然后输入 http://127.0.0.1:8000/blog/,就可以看到页面: 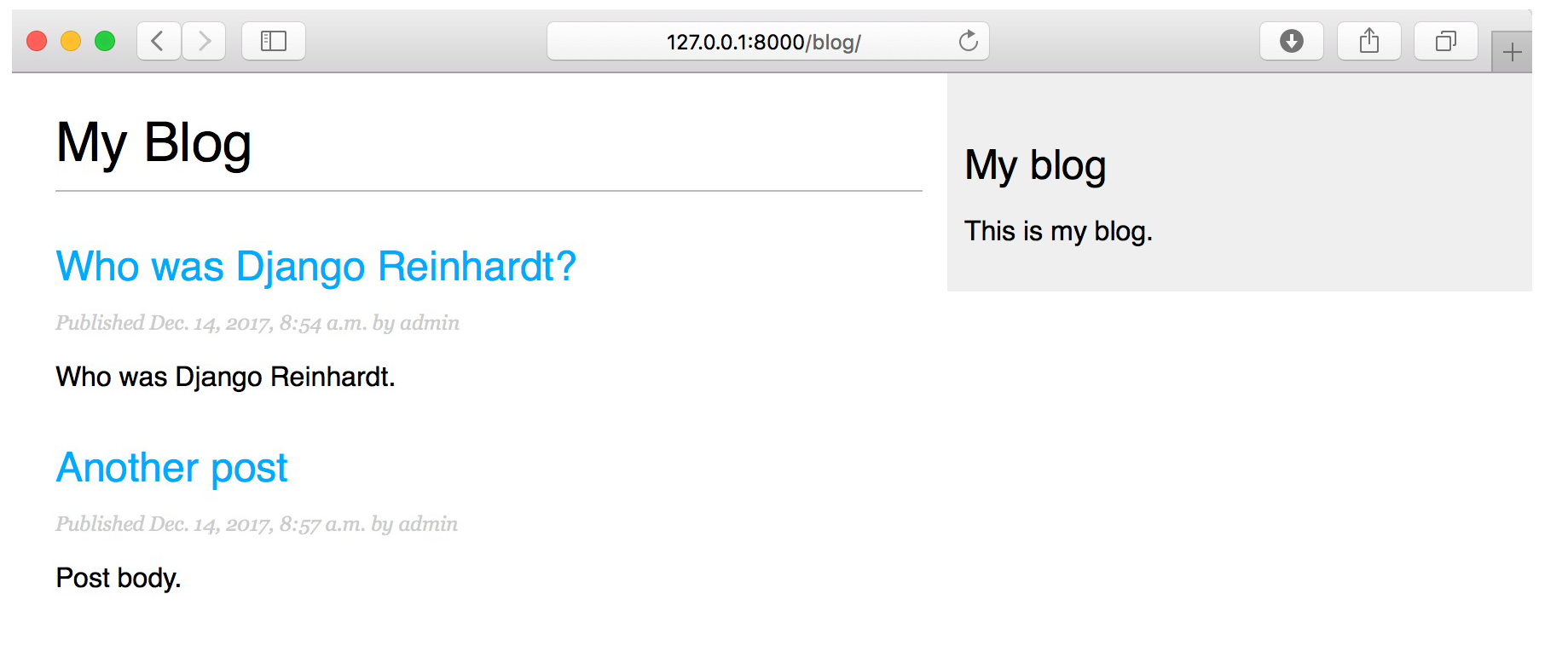 可以看到文章列表页正常工作了,显示出了所有已经发布的文章(采用了自行编写的模型管理器)。之后再编辑一下详情页,用来展示某个具体的内容。 这里要解释的是,每一个文章的URL是动态生成的,点击那个URL,就会把这些参数通过URL解析,参数一个传进去,然后找到对应的数据,展示在详情页面上:
可以看到文章列表页正常工作了,显示出了所有已经发布的文章(采用了自行编写的模型管理器)。之后再编辑一下详情页,用来展示某个具体的内容。 这里要解释的是,每一个文章的URL是动态生成的,点击那个URL,就会把这些参数通过URL解析,参数一个传进去,然后找到对应的数据,展示在详情页面上:
{% extends 'blog/base.html' %}
{% block title %}
{{ post.title }}
{% endblock %}
{% block content %}
<h1>{{ post.title }}</h1>
<p class="date">
Published {{ post.publish }} by {{ post.author }}
</p>
{{ post.body|linebreaks }}
{% endblock %}
详情页面如下图所示: 
添加分页
还有一个问题是,文章多了怎么办,不可能全部展示在同一页。 在Django1的时候制作过一个分页器,用了一个类计算,然后把分页的内容传递给页面上布置好的Bootstrap元素。这个东西在Django 2 里依然可以使用,不过这次用Django自带的分页器。 需要修改视图,导入Django的分页器,然后再设置每次传给页面的元素。
from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger
def post_list(request):
object_list = Post.published.all()
paginator = Paginator(object_list, 3) # 3 posts in each page
page = request.GET.get('page')
try:
posts = paginator.page(page)
except PageNotAnInteger:
# if page is not an integer deliver the first page
posts = paginator.page(1)
except EmptyPage:
# if page is out of range deliver last page
posts = paginator.page(paginator.num_pages)
return render(request, 'blog/post/list.html', {'page': page, 'posts': posts})
这里做的事情主要有三个:
导入分页器和对应的错误信息
实例化一个分页器对象,将需要分页的QuerySet 和 每页显示的数量传进去,这个分页器对象用.page(x)的方法拿到某一页的内容。有个属性叫做.num_pages是总页码。
try那部分的业务逻辑是先从页面拿到页码,然后取得对应页码的内容,如果页面传过来的不是整数(比如第一次进这个页面),就返回第一页。如果超出范围,就返回最后一页。
这里既然最后传给了list页面两个参数,可见又需要修改模板,由于分页需要反复使用,就新建一小块东西用来继承即可。在blog->templates目录下边新建pagination.html:
<div class="pagination">
<span class="step-links">
{% if page.has_previous %}
<a href="?page={{ page.previous_page_number }}">Previous</a>
{% endif %}
<span class="current">
Page {{ page.number }} of {{ page.paginator.num_pages }}.
</span>
{% if page.has_next %}
<a href="?page={{ page.next_page_number }}">Next</a>
{% endif %}
</span>
</div>
这一段代码解释一下:
代码的目的通过判断当前的页码,如果还有前一页,就展示一个Previous链接,如果还有后一页,就展示一个Next链接。固定展示的当前页码和总页码。
用到了新的{% if %} 和{% endif %} 判断,其实这些逻辑也可以在业务代码中完成,但是这样返回给页面的变量太多,所以有的时候在模板语言内进行逻辑是比较方便的做法。
这里又用到了新学的分页器的知识分页器对象的.page(x)返回的东西有.has_previous, .has_next, .number, .paginator.num_pages几个属性,看名字就知道意思。
之后回到list.html里,将刚编写好的分页器页面继承进来然后放在content块的下边:
{% include 'pagination.html' with page = posts %}
这一行要解释的就是没有用extends而是用include,因为上边用了,而且这是content内容的一部分,所以用了include。 后边的with page = posts,这是因为paginator.html里我们定义的变量名称叫做page,而list页面里传入的变量名叫做posts,拼起来的页面里有这两个名称,但其实是同一个东西。而视图函数传进来的变量名叫做posts,如果直接交给视图函数渲染,其中的page对于视图函数来讲是页码,所以加上with,让include进来的时候,paginator.html里的所有page名称都换成posts,视图函数在渲染list.html的时候就对应上了。 如果不太好理解的话,就不要通过include,而是将pagnitor.html里边的部分直接放进list.html,就会知道了。 分过页的页面如下: 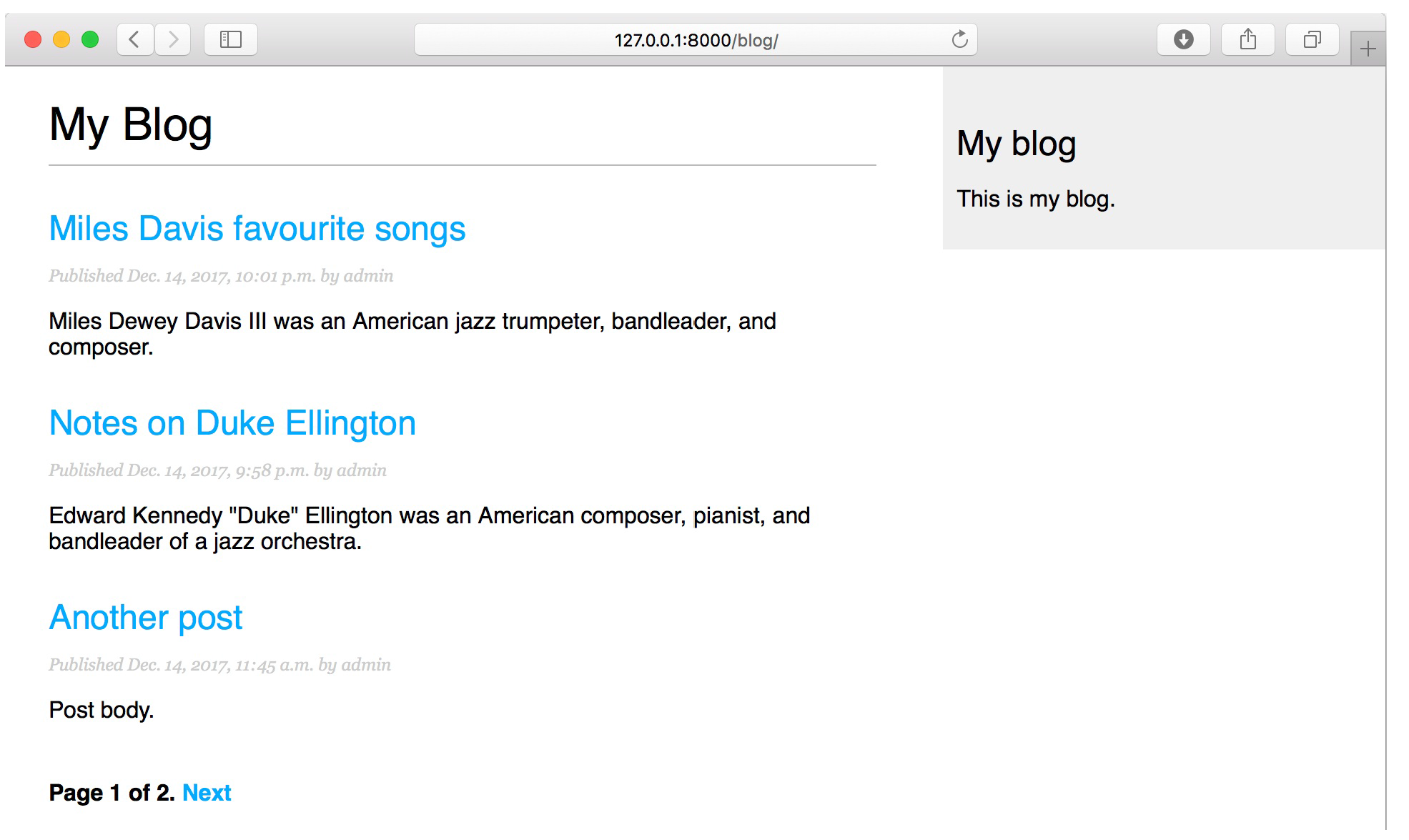
使用CBV
现在博客的雏形已经做好了,看一下CBV的概念。之前的视图是用函数写的,叫做FBV,视图也可以用类写,就是CBV,不过视图用类写的时候必须继承基类view,然后还有一些特殊的规定。 CBV相比FBV的好处是不用判断请求的类型,可以直接用get, post, put等请求直接到里边的函数。通过继承也方便大规模使用视图。这里是CBV的官方文档。 这个地方我们用Django 的 内置CBV类 ListView 来改写我们自己的post_list 视图:
from django.views.generic import ListView
class PostListView(ListView):
queryset = Post.published.all()
context_object_name = 'posts'
paginate_by = 3
template_name = 'blog/post/list.html'
这个类和post_list视图函数的功能类似 解释一下里边的参数:
这个CBV由于是继承,想要达到FBV一样的功能,要定义一些参数。这里如果想拿到全部查询结果,直接用model = Post即可用内建的Post.objects.all()查询,但是这里我们需要用自定义的模型管理器,所以用了queryset这个属性,等于我们自己查到的东西。
context_object_name指的是CBV向模板返回的模板变量的名称,如果不设置这个参数,默认的名称是object_list
还可以设置分页参数,paginate_by指的是每页的文章数目
template_name 是指定的模板名称,如果不指定,ListView用的是 blog/post_list.html
CBV写好以后,需要配置一下URL改到这个CBV:
urlpatterns = [
# post views
# path('', views.post_list, name='post_list'),
path('',views.PostListView.as_view(),name='post_list'),
path('<int:year>/<int:month>/<int:day>/<slug:post>/', views.post_detail, name='post_detail'),
]
还有一个问题是,这个CBV向页面返回的page对象的名称叫做page_obj,所以必须把包含的地方修改一下才行。 {% include 'pagination.html' with page=page_obj %} 可见这个CBV实际上传了两个模板变量posts(CBV里定义的名称)和page_obj(默认的名称)给模板,而不是我们原来的视图函数只传一个通过内置分页拿到的posts。
总结,这一部分学习了Django 2基础,包括如下内容:
django-admin startproject 建立项目
查看Django 版本与settings.py的设置
使用manage.py startapp 建立app和激活应用
使用models.py建立数据模型
通过数据模型在数据库中建立数据表:makemigration migrate和 sqlmigrate
建立超级用户和管理后台,将模型注册到管理后台
admin.py 里自定义类用于个性化管理后台
使用ORM操作数据库,增删改查
.all(), .filter(), .exclude(), .order_by()都返回一个QuerySet,可以连用
自定义模型管理器,在models.py里写类并且继承models.Manager类,在模型类里定义一个属性指向自定义的管理器
配置URL和视图函数,path可以直接用尖括号括起变量名和类型,要用正则就用re_path
做好多级路由转发,第一层路由用include包含第二层路由,并且做好命名空间
通过reverse()方法,通过模型类的方法来为每个类的实例来生成格式化的URL
模板语言的标签,变量和过滤器
模板的extends-继承与include-引入
内置分页器Paginator的使用,分页器的page对象内部包装着每一个数据行,类似QuerySet。
分页器还有一些属性用于判断是否是第一页和最后一页等各种属性,一般写在模板变量里
CBV的初步使用-内置CBV ListView。会返回查询结果和分页结果两个变量,和原来FBV不同
心得:传给模板的上下文变量不要太少也不要太多,业务逻辑和模板逻辑有效分离。业务逻辑传数据对象,模板逻辑用于拆分并展示。
心得:新的url path方法和自定义模型管理器的内容是新内容,要会用。
心得:多级路由转发一定要从一开始就规范化好,reverse()除了反向解析外还可以生成URL,这点需要好好使用。