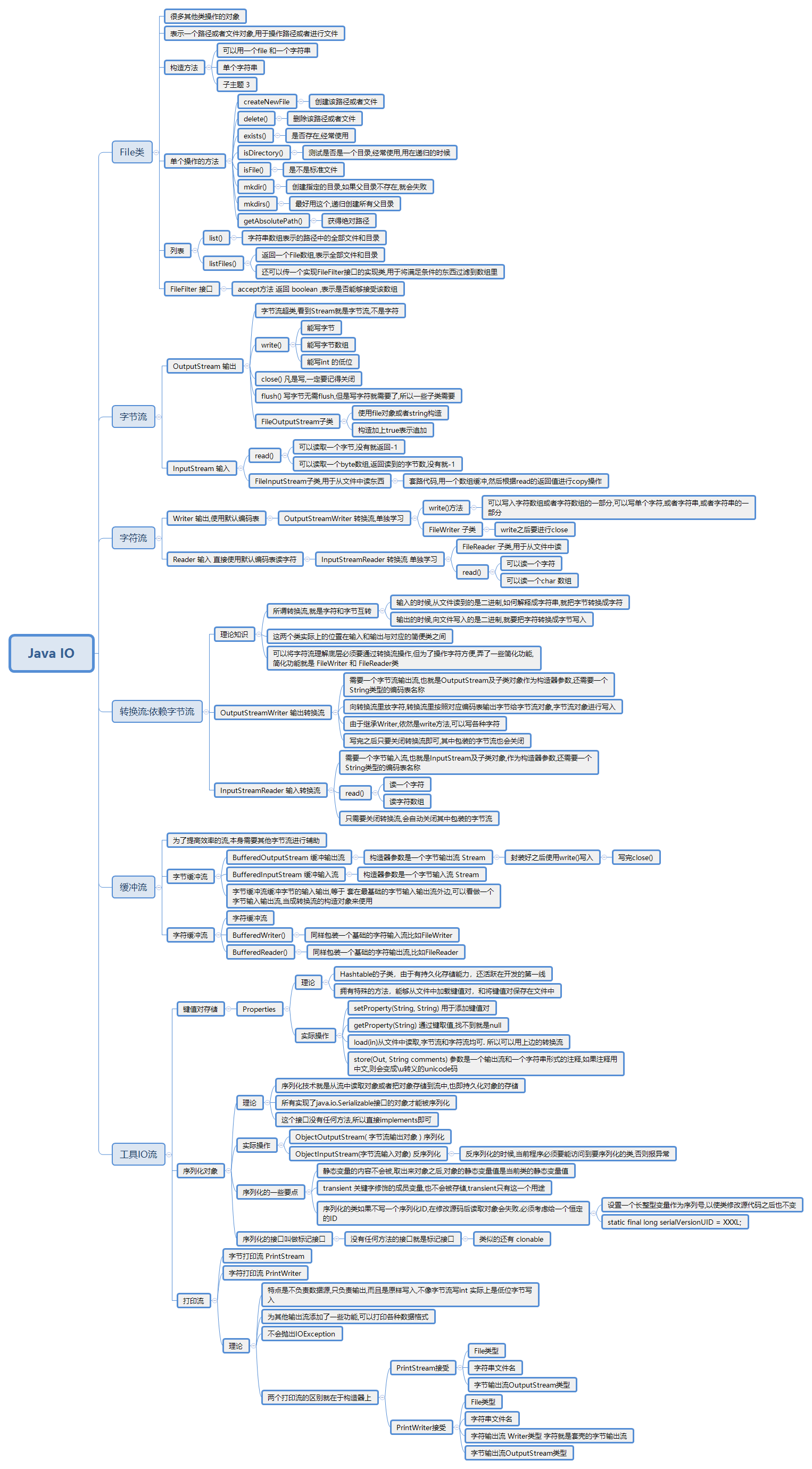
在学习Java的过程中,发现虽然库浩如烟海,但是Java的体系让学习库不是那么痛苦,不需要过度的去背API,而是采取从上至下,从抽象类,接口逐步到具体类,建立起关于一个功能的完整结构,遇到具体问题就可以知道如何下手了。
IO的部分自己整理了一个脑图,就不放上来了。这里是用最精简的方式来说一下IO。
通常Java的教学会按照包里的抽象类来将IO分成字节流,字符流,转换流等几种。实际上IO不管来自于哪里,主要就是两种操作,一是操作字节,二是操作字符。这这几种流,只是一个过程中的不同节点而已。
操作字节最简单也最容易理解,就是二进制数据,底层怎么来,怎么发过去,中间没有任何需要转换的部分,只存在操作,往深了说就是用int的低位去当成一个字节写入,当然愿意的话使用byte类型也没问题。
操作字符相比操作字节,只不过多了一个解码编码的过程,由于程序进内存,发送数据,写入硬盘,都是二进制。因为是字符,所以中间加了一道给人看的转换,仅此而已。
了解了这个,其实就会发现,字符流和字节流其实是统一的,因为一个流的发起到结束,实际写的都是二进制数据。这也就不难理解为什么转换流是字符流的子类,然后又需要一个字节流的对象作为构造器的参数。毕竟最后还是需要操作二进制数据,给字节流套了一个解释成字符的外衣,就变成字符流了。
用一句话来总结,IO就是:
字节流--转换流--字符流--我们在屏幕上看一眼--字符流--转换流--字节流。
如果不涉及编码问题,那就是字节流直接对着字节流。
其他的一些缓冲区,序列化等都是一些技术了,本质上还是先搞出数据,再整成想要的编码,搞明白了字符编码体系,IO就容易多了。
如果再加上缓冲流的话,缓冲流相当于一个在基础的字节流和字符流外边套了一个壳。实际上通过上边的分析可以发现,完全不需要直接的字符流,只需要字节流配上转换流,弄成Java里的char类型或者字符串,然后想做什么就做什么了。
包装方法就像下边这样:
FileInputStream fis = new FileInputStream("D:\\gbk.txt");
BufferedInputStream bis = new BufferedInputStream(fis);
InputStreamReader isr = new InputStreamReader(bis, "GBK");
FileOutputStream fos = new FileOutputStream("D:\\utf.txt");
BufferedOutputStream out = new BufferedOutputStream(fos);
OutputStreamWriter osw = new OutputStreamWriter(out, "UTF-8");
在IO流的转换中,其实还隐含了字节---以字符集编码转换成UTF-16--再转换成其他字符集的字节这样一个过程。因为在过程中,都是需要以字符串或者char类型来处理字符,由于Java内部的char类型就是UTF-16,说明虚拟机也是使用的UTF-16,因此并不是直接将一种字节转换成另外一个字节,只要通过了Java程序处理,就隐含的转成了UTF-16。
好了,马上要进入多线程的环节了。这个在Python里没怎么深入过,这次要看看了。想到后边的Java EE和Spring,嗯,漫漫长路其修远兮。
2月20日更新,毕竟知识点还是很多,为了免去经常要查API,放一个自己做的脑图: